
Od ponad dekady różne platformy z danymi uważa się za kluczową część marketingu cyfrowego i zautomatyzowanego.
Narzędzia takie jak platformy skupiające dane klientów (CDP) i platformy zarządzania danymi (DMP) odgrywają ważną rolę w prowadzeniu targetowanych kampanii reklamowych, generowaniu szczegółowych raportów, określaniu atrybucji i pomaganiu wydawcom i reklamodawcom w lepszym zrozumieniu swoich odbiorców.
Kolejnym ważnym elementem tych platform jest jezioro danych (data lake). To scentralizowane repozytorium, które umożliwia przechowywanie wszystkich ustrukturyzowanych i nieustrukturyzowanych danych w jednym miejscu. Dane zebrane w data lake można przesłać do CDP lub DMP i wykorzystać między innymi do tworzenia grup odbiorców.
W tym poście na blogu przyjrzymy się, czym są platformy CDP, DMP oraz data lake. Ponadto opowiemy o tym, kiedy budowanie tych narzędzi ma sens. Na koniec sprawdzimy sposoby ich tworzenia w oparciu o nasze doświadczenie.
Dlaczego powinieneś budować CDP lub DMP?
Chociaż na rynku istnieje wiele platform skupiających dane klientów (CDP) i platform zarządzania danymi (DMP), niektóre firmy potrzebują zbudować własne narzędzie, aby zapewnić sobie kontrolę nad gromadzonymi danymi, własnością intelektualną i funkcjami.
Oto kilka przykładowych sytuacji, w których budowanie CDP lub DMP ma sens:
- Jeśli twoja firma działa w branży AdTech lub MarTech i chce rozszerzyć lub ulepszyć swoją ofertę technologiczną.
- Jeśli jesteś wydawcą i chcesz zbudować zamkniętą platformę z treściami (jak Facebook), aby zarabiać na własnych danych i umożliwić reklamodawcom docieranie do odbiorców.
- Jeśli jesteś firmą, która zbiera duże ilości danych z wielu źródeł i chcesz mieć prawo własności do technologii oraz kontrolę nad rozwojem produktu i jego funkcji.
Co to jest platforma skupiająca dane klienta (CDP)?
Platforma skupiająca dane klienta (CDP) to technologia używana w branży marketingowej. CDP gromadzi i porządkuje dane z różnych źródeł online i offline.
Platformy CDP są zwykle używane przez marketerów do zbierania wszystkich dostępnych danych o kliencie i przechowywania ich w jednej bazie danych. Baza ta jest zintegrowana z innymi systemami używanymi w firmie.
Dzięki CDP marketerzy mogą przeglądać szczegółowe raporty analityczne, tworzyć profile użytkowników, grupy odbiorców, dokonywać segmentacji, przeglądać widoki pojedynczych klientów (Single Customer View, SCV), a także modyfikować kampanie reklamowe i marketingowe, eksportując dane do innych systemów.
Na poniższej infografice zobrazowaliśmy anatomię CDP.
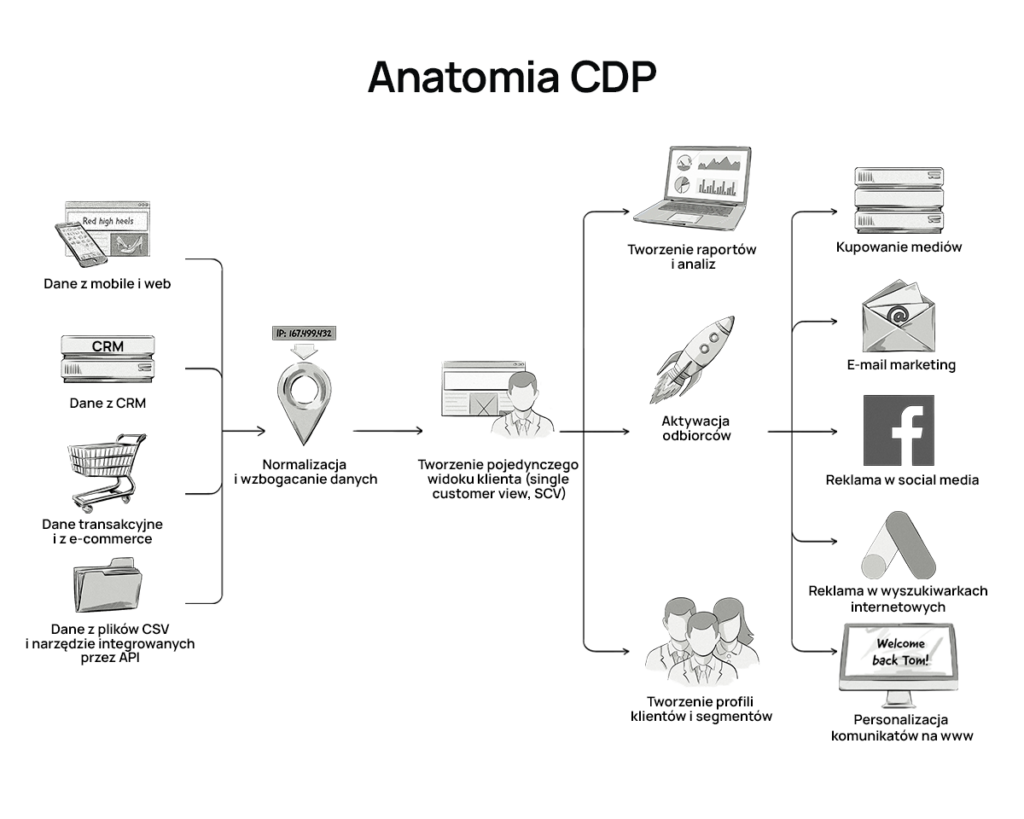
Co to jest platforma zarządzania danymi (DMP)?
Platforma zarządzania danymi (Data Management Platform, DMP) to oprogramowanie, które gromadzi, przechowuje i porządkuje dane zebrane z różnych źródeł, takich jak witryny internetowe, aplikacje mobilne i kampanie reklamowe. Reklamodawcy, agencje marketingowe i wydawcy używają DMP do ulepszania targetowania, przeprowadzania zaawansowanych analiz, znajdywania podobnych grup odbiorców (look-alike modeling) i poszerzania grona odbiorców.
Na ten infografice przedstawiamy kluczowe komponenty DMP.
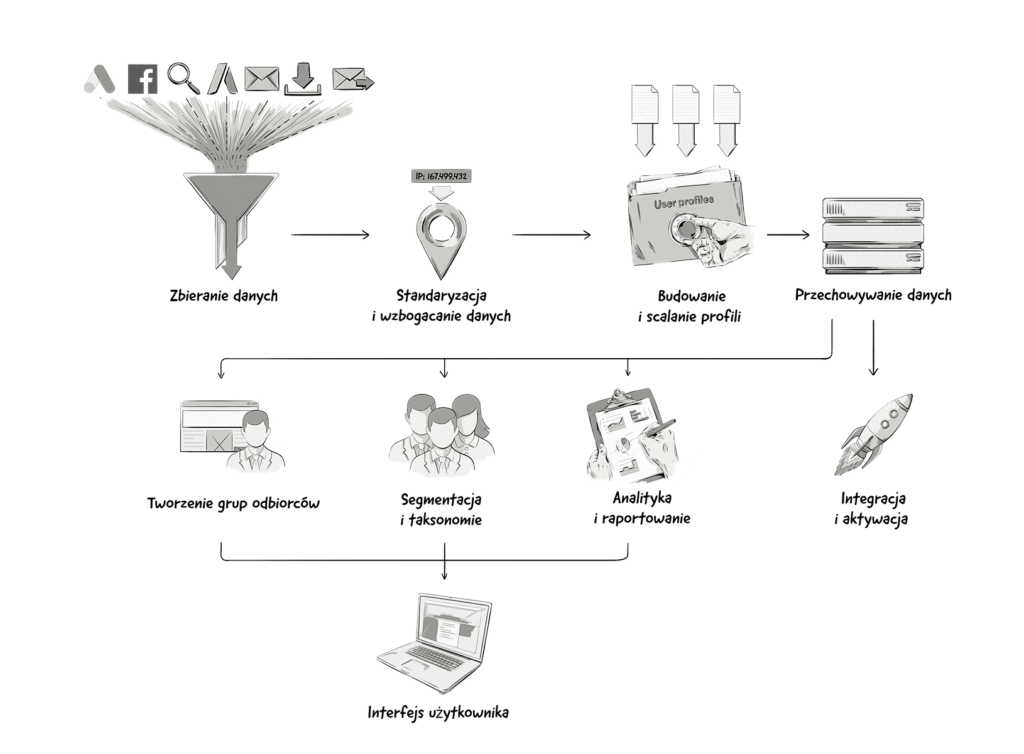
Co to jest data lake?
Data lake to centralne repozytorium dla danych ustrukturyzowanych, częściowo ustrukturyzowanych i nieustrukturyzowanych. Zwykle przechowuje się w nim ogromne ilości informacji.
Data lake jest często postrzegany jako jedyne źródło prawdy, ponieważ dane tam gromadzone są poprawnie przygotowane i zwalidowane. To także uniwersalne źródło znormalizowanych, zduplikowanych i zagregowanych danych, które są używane w całej firmie i często wymagają nadania uprawnień do ich odczytu czy zmiany.
Dane ustrukturyzowane: dane sformatowane przy użyciu konkretnego schematu. Dane ustrukturyzowane można łatwo przeszukiwać w relacyjnych bazach danych.
Dane częściowo ustrukturyzowane: Dane, które nie są zgodne ze strukturą tabeli baz danych, ale są zorganizowane tak, że ich analiza jest możliwa. Logi, CSV, XLM i JSON, e-maile, dokumenty, PDF-y, strony internetowe.
Dane nieustrukturyzowane: dane, które nie zostały sformatowane i są w stanie niezmienionym od momentu ich wprowadzane do data lake. Audio, wideo, dane obrazu, język naturalny, dokumenty.

Wiele firm posiada działy zajmujące się analizą danych lub produkty (jak CDP), które gromadzą informacje z różnych źródeł, ale wymagają wspólnego źródła danych. Takie dane często wymagają dodatkowych zabiegów, aby mogły zostać użyte do reklamy automatycznej (programmatic advertising) lub analizy danych.
W data lake dostępne są również niezmienione lub surowe dane. Dzięki takiemu podejściu do danych jesteśmy w stanie je dodatkowo weryfikować na próbnych lub pełnych zestawach danych. Posiadanie surowych danych jest również dobrą opcją, gdy musimy przetworzyć dane historyczne, które nie zostały całkowicie przekształcone.
Jaka jest różnica między CDP, DMP i data lake?
Platformy skupiające dane klientów (CDP) mogą wydawać się bardzo podobne do platform zarządzania danymi (DMP), ponieważ i te i te są odpowiedzialne za zbieranie i przechowywanie danych o klientach. Jakie są zatem różnice między nimi?
Platformy skupiające dane klientów (CDP) wykorzystują przede wszystkim dane własne (first-party data) i opierają się na prawdziwych tożsamościach konsumentów (Personally identifiable information, PII). Informacje te pochodzą z różnych systemów w organizacji i mogą być wzbogacone o informacje od partnerów biznesowych (third-party data). CDP są wykorzystywane głównie przez marketerów do pielęgnowania istniejącej bazy konsumentów.
Platformy zarządzania danymi (DMP) są przede wszystkim odpowiedzialne za agregowanie danych od partnerów biznesowych (third-party data), co zazwyczaj wiąże się z wykorzystaniem plików cookie. W ten sposób DMP jest bardziej platformą AdTech, podczas gdy CDP można uznać za narzędzie MarTech. Platformy DMP są wykorzystywane głównie do ulepszania kampanii reklamowych i pozyskania podobnego rodzaju odbiorców (lookalike).
Data Lake to zasadniczo system, który zbiera różne typy danych z wielu źródeł, a następnie przesyła je do CDP lub DMP.
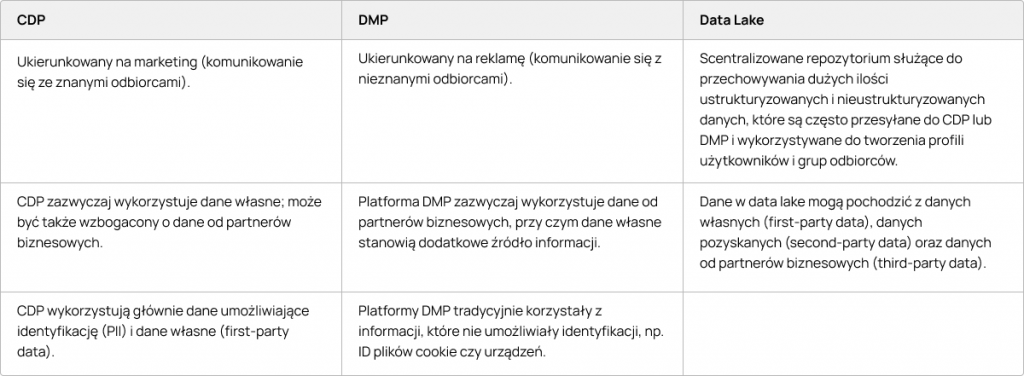
Jak najczęściej używa się CDP, DMP i data lake?
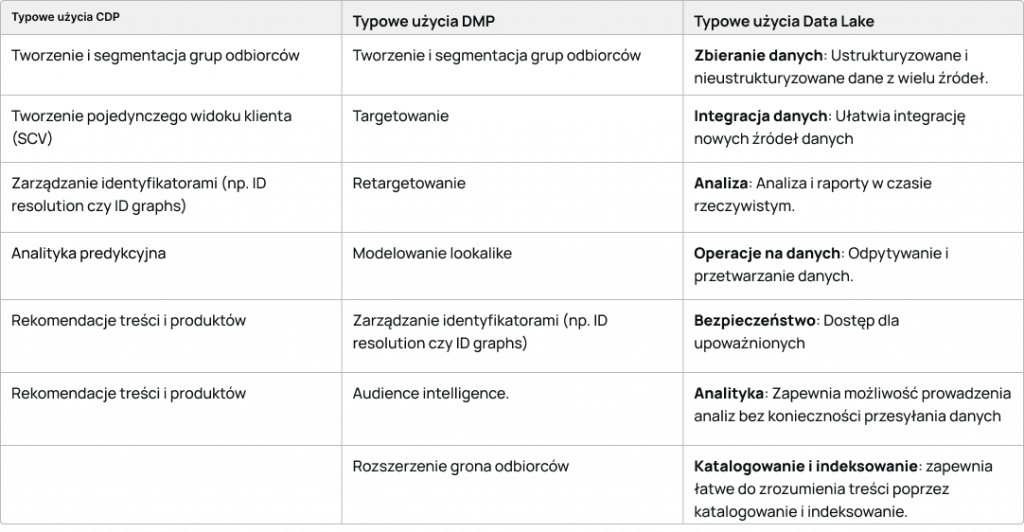
Jakie typy danych gromadzą platformy CDP, DMP i data lake?
Rodzaje danych gromadzonych przez CDP, DMP i data lake obejmują:
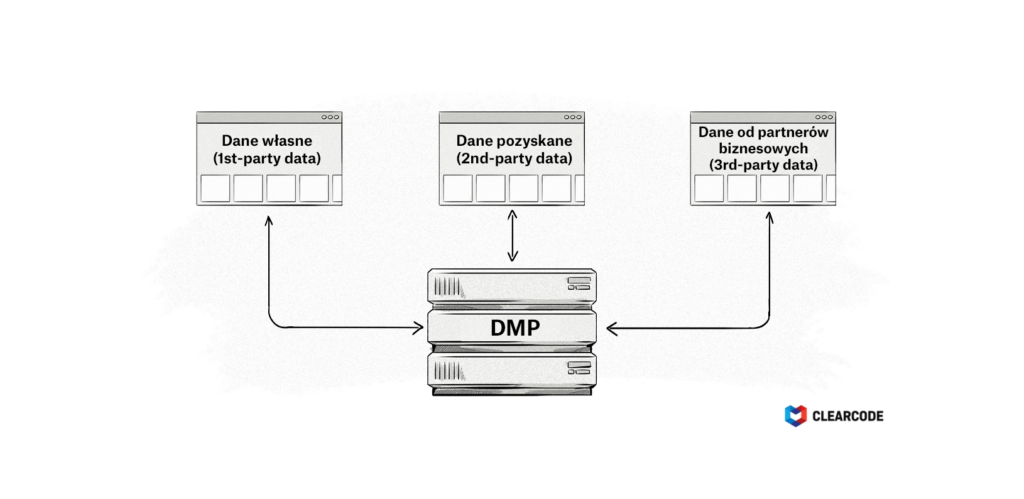
Dane własne (first-party data)
Dane własne to informacje zebrane bezpośrednio od użytkownika lub klienta i są uważane za najcenniejszą formę danych, ponieważ reklamodawca lub wydawca ma bezpośrednią relację z użytkownikiem (np. użytkownik już zaangażował się i wszedł w interakcję z reklamodawcą).
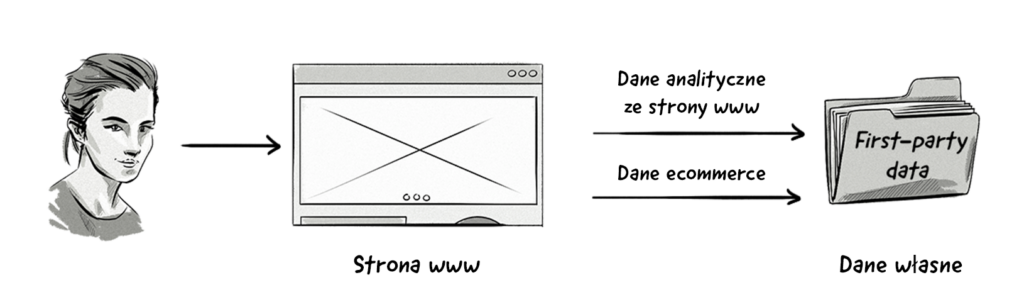
Dane własne są zazwyczaj zbierane z:
- Narzędzi do analityki internetowej i mobilnej.
- Systemów zarządzania relacjami z klientami (CRM).
- Systemów transakcyjnych.
Dane pozyskane (second-party data)
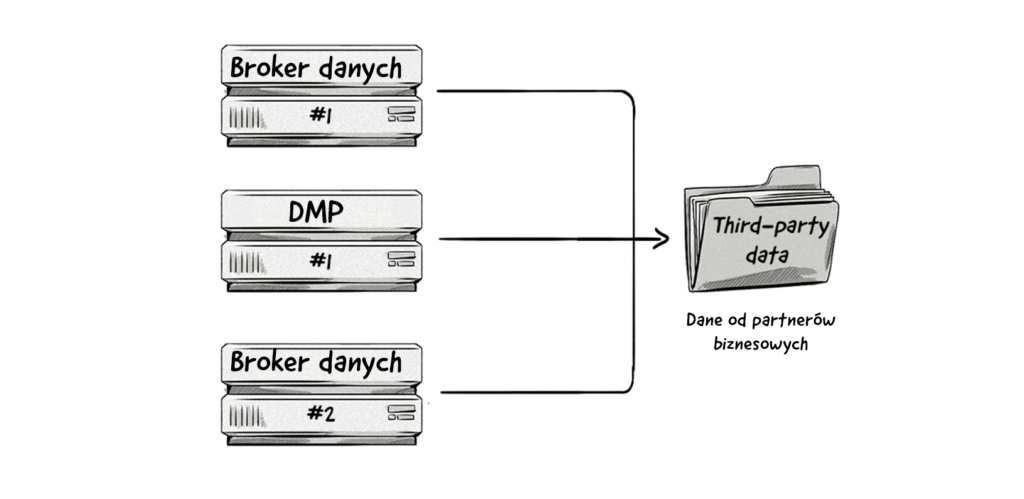
Wielu wydawców i sprzedawców zarabia na własnych danych, dodając zewnętrzne narzędzia śledzące do swoich witryn internetowych lub śledząc pakiety SDK w swoich aplikacjach i przekazując dane o swoich odbiorcach brokerom danych i platformom DMP.
Dane te mogą obejmować historię przeglądania użytkownika, interakcję z treścią, zakupy, informacje o profilu wprowadzone przez użytkownika (np. płeć lub wiek), geolokalizację GPS i wiele innych.
Na podstawie tych zestawów danych brokerzy danych mogą tworzyć zestawienia informacji dotyczące zainteresowań, preferencji zakupowych, grup dochodowych, danych demograficznych itp.
Dane mogą być dodatkowo wzbogacane przez dostawców danych ze świata offline, takich jak firmy obsługujące karty kredytowe, agencje oceny kredytowej czy firmy telekomunikacyjne.
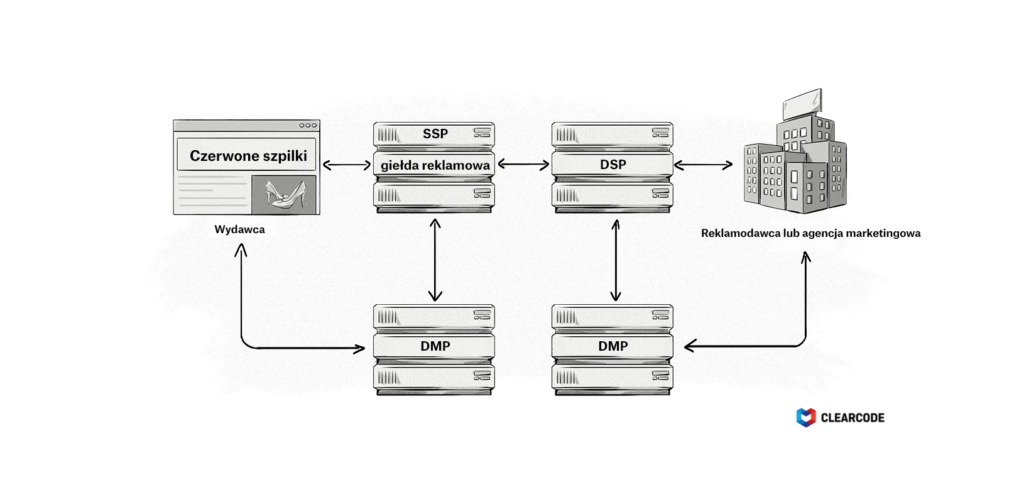
W jaki sposób dane są gromadzone na platformach CDP, DMP i data lake?
CDP, DMP i data lake najczęściej gromadzą dane w następujące sposoby:
- Integracja z innymi platformami AdTech i MarTech poprzez połączenie serwer do serwera lub do API.
- Dodanie tagu (czyli fragmentu kodu JavaScript lub piksela HTML) do witryny reklamodawcy lub wydawcy.
- Import danych z plików np. CSV, TSV, parquet.
Najczęstsze wyzwania techniczne i wymagania podczas budowania DMP lub CDP
Zarówno CDP jak i DMP umożliwiają przetwarzanie dużych ilości danych w ramach swoich struktur. Im więcej danych CDP lub DMP może wykorzystać do tworzenia segmentów, tym są one cenniejsze dla użytkowników (np. reklamodawców, naukowców zajmujących się danymi, wydawców itp.).
Jednak im większa skala, tym bardziej złożona konfiguracja infrastruktury danej platformy. Zaprojektowanie infrastruktury zależy od skali i ilości danych, które będą docelowo przetwarzane.
Poniżej opisaliśmy kluczowe elementy, które należy wziąć pod uwagę przez budową CDP lub DMP.
Strumień źródła danych
Strumień źródła danych (data-source stream) pozyskuje dane od użytkowników/odwiedzających. Dane te muszą być gromadzone i przesyłane do serwera śledzącego (tracking server).
Źródłami danych mogą być:
- Dane witryny: zdarzenia w przeglądarce użytkownika (sprawdzane przez kod JavaScript). Jeśli odwiedzający podejmuje jakąś akcję (np. klika), kod JavaScript stworzy tzw. payload (podsumowanie tych akcji) i wyśle go do komponentu śledzącego.
- Dane aplikacji mobilnych: dane własne wysyłane przez SDK. Mówimy o danych pozwalających na identyfikację użytkownika (PII), atrybuty profilu użytkownika, a także dane dotyczące jego zachowania. Te ostatnie odnoszą się do określonych działań w aplikacjach mobilnych. Dane wysyłane z SDK są zbierane przez komponent śledzący.
Integracja danych
Z CDP i DMP można zintegrować wiele źródeł danych:
- Integracja danych własnych (first-party data integration): odnosi się do danych zebranych przez moduł śledzący oraz danych z innych platform.
- Integracja danych pozyskanych (second-party data integration): Dane są pozyskiwane dzięki integracji z systemami dostawców danych (np. firm sporządzających raporty kredytowe); te dane można wykorzystać do wzbogacenia informacji o profilu.
- Integracja danych od partnerów biznesowych (third-party data): odnosi się zwykle do modułów śledzących partnerów biznesowych, np. pikseli i skryptów w witrynach internetowych oraz pakietów SDK w aplikacjach mobilnych.
Ilość profili
Wiedza o ilości profili, które będą w CDP lub DMP, ma kluczowe znaczenie przy określaniu typu bazy danych potrzebnej do przechowywania profili.
Zadaniem bazy danych profili jest rozpoznawanie tożsamości klienta. Dzięki temu możliwe jest łączenie profili klientów (deduplikacja) oraz przypisanie ich do właściwych grup odbiorców. To kluczowy element infrastruktury CDP lub DMP.
Ekstrakcja i odkrywanie danych
Typowym użyciem dla CDP i DMP jest dostarczenie interfejsu dla naukowców zajmujących się danymi, aby mieli wspólne źródło znormalizowanych danych.
Oczyszczone (z niepotrzebnych informacji) i zdeduplikowane źródło danych to cenny wkład, który można wykorzystać do przygotowania danych do uczenia maszynowego. Wówczas nieodzowne jest stworzenie data lake, w którym dane są przekształcane i kodowane do postaci zrozumiałej dla maszyn.
Istnieje wiele rodzajów transformacji danych, takich jak:
- OneHotEncoder
- Haszowanie
- LeaveOneOut
- Target
- Ordinal Integer
- Binarne
Wybór odpowiedniego typu transformacji danych i zaprojektowanie dobrego pipeline-u do uczenia maszynowego wymaga współpracy zespołu programistów z analitykami danych.
Na bazie uczenia maszynowego można tworzyć modele przewidywania zdarzeń (event-prediction model), a następnie wykorzystać je w operacjach klastrowania i klasyfikacji oraz agregowania i przekształcania danych. W ten sposób odkrywane są wzorce zachowań. Początkowo są one niewidoczne dla ludzkiego oka, jednak stają się dość oczywiste po przekształceniu danych (np. transformacji hiperpłaszczyznowej).
Segmenty
Rodzaje segmentów, które będą obsługiwane przez CDP i DMP, również mają wpływ na projekt infrastruktury.
Typy segmentów mogą obejmować:
- Segmenty oparte na atrybutach (dane demograficzne, lokalizacja, typ urządzenia itp.)
- Segmenty behawioralne oparte na zdarzeniach (np. kliknięcie w link w wiadomości e-mail) i ich częstotliwości (np. odwiedzenie strony internetowej co najmniej trzy razy w miesiącu)
- Segmenty na podstawie klasyfikacji wykonanej przez uczenie maszynowe:
- Podobieństwo/powinowactwo: Celem modelowania podobieństwa/powinowactwa jest wspieranie funkcji poszerzania grona odbiorców. Rozszerzanie grona odbiorców może opierać się na różnych danych wejściowych i być napędzane podobnymi funkcjami. Wyobraź sobie samodoskonalącą się pętlę, w której wybieramy profile z dużą liczbą konwersji i tworzymy odbiorców o podobnych zainteresowaniach. Skutkuje to większą liczbą konwersji, które można wykorzystać do tworzenia większej liczby profili podobieństwa itp.
- Predykcja: Targetowanie predykcyjne wykorzystuje dostępne informacje do przewidywania możliwości wystąpienia interesującego zdarzenia (zakupu, instalacji aplikacji itp.) i targetowania reklam tylko na profile o wysokim współczynniku przewidywania.
Najczęstsze wyzwania techniczne i wymagania podczas budowania data lake
Na jakie wyzwania możesz trafić podczas budowania data lake?
- Trudno jest połączyć wiele źródeł danych tak, aby dostarczać przydatne informacje, na których można dokonywać dalszych operacji. Zwykle używa się do tego ID by połączyć różne źródła danych. Wyzwanie polega na tym, że ID często po prostu nie są dostępne lub nie pasują.
- Kolejnym wyzwaniem jest określenie danych dostępnych w danym źródle. Czasami nawet ich właściciel nie wie, jakie dane znajdują się w tym źródle.
- Jeśli proces ETL zawiedzie, będzie trzeba również posprzątać dane i ponownie je przetworzyć. Tę pracę można wykonać ręcznie lub zautomatyzować. Tabele delta Databricks Delta Lake są kompatybilne z właściwościami ACID, dzięki czemu firma oferuje automatyzację takiej pracy. AWS również wdraża transakcje ACID w jednym ze swoich rozwiązań (governed tables).
W pierwszym etapie transformacji dane są wyodrębniane i ładowane do tzw. raw stage. Po zakończeniu wstępnego procesowania, często dostępne są dodatkowe warstwy przetwarzania danych.
Drugi etap umożliwia różne przekształcenia danych: deduplikację, normalizację, ustalanie priorytetów na kolumnach czy scalanie. Te fazy tworzą dodatkowe warstwy transformacji danych np np. agregacje na poziomie biznesowym potrzebne dla data science albo do raportów.
Używając komponentów data lake od AWS, np. Amazon Lake Formation, który wykorzystuje mechanizm przechowywania S3, z Amazon Glue lub Amazon EMR do procesów ETL, jesteśmy w stanie stworzyć scentralizowane, nadzorowane i zabezpieczone repozytorium danych.
Oprócz Amazon Lake Formation, jest też Amazon Athena -interfejs, którego można używać między wieloma komponentami infrastruktury. Amazon Athena zapewnia ujednoliconą metodę dostępu do danych Amazon Lake Formation.
Ponadto, korzystając z zabezpieczeń IAM, do data lake można dodać dodatkową warstwę kontroli dostępu.
Jeśli data lake jest odpowiednio zaprojektowany i utworzony, dostęp do danych można zoptymalizować pod kątem kosztów.
Dzięki finalnemu etapowi agregacji danych, możemy wykonać wymagane operacje tylko raz w trakcie procesu ETL, gdy jest to wymagane.



