
Do you have your code repositories? What about the data? How do you collect them? Yes, we know, it’s not that easy. When data comes from multiple sources, with different formats, and arrives at different frequencies, then you need specialized tools for specific tasks. There are many tools, but in this blog post we’ll tell you about our production solution we built on AWS.
The goal was this: Collect data from multiple sources and allow it to be used to show targeted ads to users watching videos on our client’s platform.
What Is a Data Lake?
Basic Information
Data accompanies us at every step. When we turn on our phones and laptops or buy parsley, information about these activities is saved somewhere.
According to Nate Silver, a well-known statistician and editor-in-chief of FiveThirtyEight, we produce the equivalent of the amount of data that the Library of Congress has in its entire print collection three times every second.
The reason why data is called the oil of the 21st century is because it can be used to extract enormous value.
However, with large amounts of data, problems arise. So what can we do with it? Well, we first need to put it in order.
Imagine a corporation that has many different departments and in each of them a different system. This results in a huge variety of data being collected and stored in various formats, such as:
- Flat files — CSV, logs, XML, JSON.
- Unstructured data — e-mails, documents, PDFs.
- Binary data — pictures, sound, video.
- Structured — databases.
Each department and system has to share data with each other and they all have their own way of sharing this data.
Also, some sets of data might have already been processed while others are still raw. It’s a total mess. This is where a data lake solves the frustrating challenge of storing and sharing this data.
A data lake provides you with the following:
- Data operations: Polling and processing.
- Security: Access control to authorized persons.
- Analytics: Provides the possibility of running analysis without the need for data transfers.
- Constant data traffic: Handling a large increase in files is not a problem.
- Cataloging and indexing: It provides easy to understand content via cataloging and indexing.
The great flexibility in this solution is the fact that we have Schema-on-Read (i.e. we model the schema only when reading), compared to a data warehouse where the Schema-on-Write approach is used (i.e. we decide on the structure when writing).
Since the 1980s, data warehousing has been widely regarded as the primary means of extracting knowledge from big collections of data. From the beginning, they also had one big disadvantage, which is costs.
With a data lake, we can store very large amounts of data cheaply and then transform them only when there is a need to adapt them to the expected structures.
The Various Lake Vendors
Data is stored on Azure Blob Storage, with a hierarchical namespace. The data analysis and processing is carried out using tools based on HDFS (Hadoop Distributed File System), such as:
- Azure Data Factory.
- Azure HDInsight.
- Azure Databricks.
- Azure Synapse Analytics.
- Azure Data Explorer.
- Power BI.
Azure Synapse itself also offers the possibility of constructing relational databases in column formats. Azure Data Lake is closely related to Azure Blob Storage, so the costs of Azure Data Lake are the same as Blob Storage. Additional tools for data analysis and processing are billed separately.
Qubole
Qubole puts a lot of emphasis on open source and isn’t dependent on a vendor (i.e. there’s no vendor lock-in). Thanks to this, the solution offered by Qubole is independent of the cloud and can be transferred to any cloud service provider.
The integrated UI is adapted to different roles in the project (e.g. data science and data engineers). This solution is available on platforms such as AWS, Google Cloud, Microsoft Azure and Oracle Cloud.
It also has a lot of integrations with various external services. The data is stored in formats like Parquet and ORC in a selected storage space (cloud or on-premises).
Technologies such as Apache Spark can be used to process data, while metadata related to the stored data can be stored in a data directory such as Apache Hive. Managing data permissions and data security can be achieved by using technologies such as Apache Ranger and Apache Sentry.
With this solution, the price is based on the number of Qubole compute units per hour, which scale according to the size of the instance used to process the data. The computing costs of these instances, as well as networking and data storage, must be paid separately to the selected cloud service provider.
Intelligent Data Lake (Informatica)
Intelligent Data Lake is based on technologies such as Apache Hive, Apache HDFS, and Apache Hadoop. It can be combined with various other data storage solutions from providers like AWS, Microsoft Azure, Google Cloud Platform and Snowflake. It provides an easy-to-use interface and requires little code writing. Information about the costs can be obtained by contacting them.
Infor Data Lake provides its own metadata catalog and internal management of this catalog, including the creation of a meta graph showing the dependencies between individual data sources or sets.
Reliable monitoring and integration with other services is also offered by Infor to ensure a trouble-free operation of the data lake. The example implementation presented by Infor is based on AWS, but it uses only EC2 instances and builds the entire Infor solution on them. Information on costs can be obtained by contacting them.
Here we have the creator of Apache Spark (distributed computing platform), who, apart from creating its own solution, has also combined it with a data warehouse, called Lakehouse.
They boast that their Delta Lake complies with ACID principles and offers data versioning, alteration, validation, as well as small-file compaction.
The ability of Presto to query Delta Lake tables for distributed SQL queries is continually evolving and is only problematic for tables with partitioned data. The cost of this solution depends on the cloud platform you are using (three are available: AWS, Azure, and the Google Cloud Platform).
You pay per DBU (Databricks Unit), i.e. the unit representing the consumption of processing power on the Databricks platform, and of course for cloud resources.
AWS Data Lake is a combination of several services available on AWS and allows you to manage data using the AWS Lake Formation services. The S3 service is used for data storage and Amazon Glue is the recommended solution for cataloging and processing data (using Apache Hive and Apache Spark technologies). The Amazon Athena service (distributed SQL queries based on Presto) is used as an interface for the data.
An integration with the EMR data processing service is currently in beta, but is ready to use. The use of Lake Formation itself is free of charge, while fees are charged for using other Amazon Web Services.
AWS Lake Formation and Others — The AWS Recipe for a Data Lake
In the past (up until August 2019), separate IAM permissions for tables, databases, and directories were used to manage access to tables in the Glue metadata catalog, which are granted to roles and users. LakeFormation was designed to centralize the management of this access, but there is an option to disable Lake Formation at the AWS account level and revert to the old way of managing access.
Below is an example of the permissions users need to access the table.

In the old approach, the role or the user must have the appropriate rights to the tables and access to the data source (e.g. S3 bucket) that is described by the tables. With this new approach, the data source is registered as a Data Lake resource, where an internal Lake Formation service role is attached to the data source and has the appropriate permissions for it.
Permissions for specific roles or users are granted to tables or databases in a very similar way to granting permissions in SQL databases (e.g. SELECT, INSERT, DROP TABLE).
When using a table, e.g. during the course of data processing, if a given user or role has the appropriate privileges to the table, access to the data source (e.g. an S3 bucket) is given via the internal Lake Formation role. Because of this, the person working with the given tables does not have direct access to the data on S3, but can only use Glue tables as an interface to work with the data.
In addition, individual users or roles can be assigned different rights, as well as rights to grant rights to other users and roles. In this case, access management becomes convenient and centralized.
It is also possible to grant permissions only to individual table columns, which is very important when working with sensitive data. AWS also has several predefined templates for retrieving data from relational databases.
Lake Formation, as a relatively new product, unfortunately has its drawbacks.
Integration with the EMR service is still in beta, so if you prefer to use a clean Spark and reduce costs by using cheaper spots on EC2 instead of Glue, then you have to take into account the need to create some workarounds in the infrastructure — mainly grant direct access to S3 buckets.
If EMR is to be used by data science teams or for data science, EMR remains a good option as an integration with Lake Formation. If users are using SAML authentication, then it works fine.
Another drawback of this solution is the lack of automation in the management of the tables themselves.
Unlike Databricks, Glue tables on AWS do not have ACID transactions implemented and there is no automatic merging of small files into larger ones, which increases the efficiency of table querying.
AWS, however, has developed an approach to its Data Lake solution (view the preview here) with governed tables that mentions the introduction of ACID transactions and automatic merging of smaller files.
What Was the Problem We Needed to Solve?
Our client was a company offering video-streaming services to the Asian market. When we started the project, it ‘only’ had about 150 million active users, and currently there are 300 million.
Each of them generates a lot of information about their preferences.
By preferences, we mean favorite types of movies, actors, etc. This information isn’t enough to use for targeted advertising, so it is also worth analyzing data such as device type, gender, and age. This can be used to create a user profile and show ads to users that they could be potentially interested in.
The client asked us to build an AdTech stack that will allow them to become a walled garden, whereby they collect customer data and monetize it. Our client suggested that a data lake was needed in this system.
Here we will only discuss a small part of this system that was designed to collect data from various sources, which was the basis for creating user profiles and their classification.
The Challenges of Our Problem
Problematic Data Sources
The data lake collected data from six different sources. Some of them came from websites and others from external companies. It is a very common practice to expand the classification possibilities. Such data can be combined, for example, by cookies or an analysis of similar characteristics.
The data lake collected the data in the following ways:
- Directly downloading the data from our customer’s databases.
- Pushing the data into our S3 buckets by the customer.
- Receiving the data from our customer’s S3 buckets.
For this particular project, there were no files processed in real-time. The frequency of the data download was imposed on us in advance by the client and external sources. In a worst-case scenario, 3 days could have passed from the time we received the data to the time we sent it to the ad server. During this time, we would have also downloaded files, processed them, and created profiles and audiences.
We divided the collected files into two stages:
- Bronze: Raw data directly from the source (unchanged).
- Silver: Cleaning, flattening of nested structures, and transformations.
Connections to DynamoDB and MongoDB turned out to be poorly supported by AWS, so we decided that it would be easier to send the data to our S3 buckets.
We received the files regularly and thanks to that we had raw data with us. We were sure that they were ours and that no one would change them. The situation was completely different with the files that we were supposed to download from the client’s S3 bucket.
At first, we decided to categorize this data as “our bronze stage” data, which we later learned was a mistake.
The raw files served as the source for the next stage, so we ran the ETL scripts directly on them. We did not anticipate backfilling on these files, i.e. replenishing old files with new data.
Existing files that related to events from 7 days ago were updated. This was done by deleting old files and replacing them with new ones with the same name.
Our workflow was every few hours, so we didn’t use the updated data from a few days ago at all. It would be problematic to use these changes because we would have to know what exactly changed in the files that have already been processed and uploaded to other services.
However, aside from data loss, we had a problem with errors during the transformation.
Pyspark was throwing up an exception when it was trying to transform files that no longer existed. We solved this by copying these files to our account. This was not the only problem we had with these files.
The files contained a lot of garbage data and the addition of metadata to treat them as tables created about 2,000 columns. There were columns containing the following types:
- session
- session_1
- session_1_2
- session_string
- session_string_1
Each of these columns could have the required session ID for the profile. We needed to conduct an in-depth analysis to see whether there was any required information for the profiles.
Good Logical Separation of Individual Parts of the System
During the development of our data lake, we used AWS CDK — a library recommended by AWS — which enables infrastructure definition using code. The current supported languages are JavaScript, TypeScript, Python, Java and C #, which can all build AWS CloudFormation templates.
Initially, we defined all AWS resources in one CloudFormation stack, but as the project grew, there was a need for a logical division of the code that would improve its readability and facilitate development. We decided to split the CloudFormation stack into several smaller ones, with precisely defined functions:
- A stack with roles and users — common for all deployments in which users and IAM roles are created, used by external servers or external users.
- The main stack — it creates internal roles used by services such as Glue, LakeFormation, EMR or EC2. In addition, S3 buckets, VPC, and SNS notifications. Amazon Athena workgroups and the main database in the Glue catalog are also created.
- Stacks related to individual data sources — here are the Glue tables created for individual data sources, as well as entire Glue data flows (workflows), containing the relevant Triggers, Jobs and Crawlers; everything needed to process data and make it available to external services.
- A stack related to monitoring — here a dashboard is created in the CloudWatch service, which presents selected metrics important for a data lake. In addition, this stack also defines CloudWatch Event Rules, thanks to which we are notified if a Job or Crawler ends its operation with errors.
- A stack related to MWAA variables — at some point in the project there was a need to use the MWAA (Managed Workflows for Apache Airflow) service, which is not available in the same region where we deployed our data lake. This stack is designed to create parameters in the Systems Manager service that can pass variables for resources deployed in the data lake to another region where the MWAA service was running.
- A stack related to unused features — the stack needed to deploy some changes to existing stacks, more details about it will be described below.
Creating multiple stacks in one AWS CDK application and transferring resources from one stack to another is relatively easy. Unfortunately, it is not without its problems.
The stacks are dependent on each other, so their deployment must be in the correct order. Resources are transferred between stacks thanks to the automatic creation of CloudFormation exports and imports by AWS CDK.
If the stacks are deployed for the first time, then it doesn’t cause any problems. However, if the stacks already exist, then deployment causes them to be updated.
If that is the case, then AWS CDK may try to remove an export that has already been imported in a different stack. Unfortunately, this causes the entire deployment to fail.

As shown in the figure above, stack B depends on stack A, so during deployment, stack A will be updated first, then stack B.
If stack B no longer needs a resource from stack A (e.g. an S3 bucket), AWS CDK will remove the bucket export from stack A’s CloudFormation template and also remove the import bucket from stack B’s template.
However, during the deployment, stack A will be updated first and removing the export from it will fail, because stack B still needs to be updated.
In this case, the deployment will not even reach the stage where it will update stack B!
To solve this problem, you can just remove stack B, then stack A will update correctly, and then stack B will be recreated. In production, however, it may happen that we cannot afford to delete a stack that already contains data (i.e. stack B).
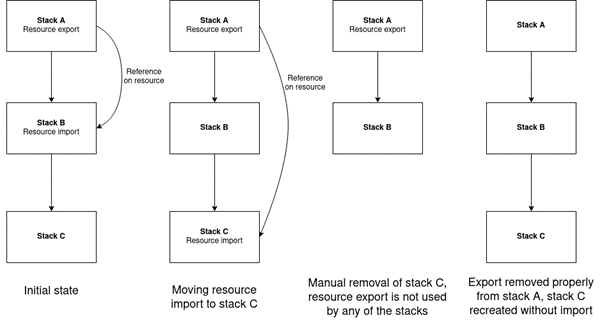
In order to solve this puzzle, we introduced stack C (it’s a stack related to unused functionalities in our code).
Stack C does not have any important functionality and can be safely deleted at any time and then recreated from scratch. Thanks to this, if stack B no longer needs the resource from stack A, then we simply make a change in the first step that removes the import of the resource from stack B and adds it to stack C.
Deployment of this change will be smooth because the export will not be removed from stack A, while imports will disappear from stack B.
In the second step, we make a change that removes the resource import from stack C.
This will also result in removing the resource export from stack A because it is not imported anywhere. However, in this case, before the deployment of this change, we can safely remove stack C. After all, this is its role.
Then the export will be safely removed from stack A, the import from stack B has already been removed in the previous step, and the auxiliary stack C will be recreated without the resource import.
Encountering similar problems with passing resource block deployments is quite rare with us and they happened only a few times during the entire year of work on the data lake, but it is worth being prepared for them.
Blueprints Only From AWS Console
In our approach, where we wanted to have everything deployed by our code, there was a problem with Blueprints, which AWS offers for the purpose of downloading data from external databases. The service makes work much easier because it does not require playing with drivers for the most popular engines.
However, AWS CDK did not offer any constructs for this service. When we started implementing this functionality, we already had a couple of dataflows in place for Glue.
We decided to use them and extend them so that we could use PySpark scripts, which were made available by AWS to the public. By uploading them as job source code and creating our own abstractions, we were able to create “our own” Blueprints from the code.
When Working With AWS Glue, Knowledge of Pyspark Is Highly Recommended
AWS heavily advertises the Glue service as a simple ETL scripting solution using an abstraction over Spark’s DataFrame — DynamicFrame. DynamicFrame from Glue does not require a predefined schema, but creates it automatically based on the data it reads.
This undoubtedly makes it easier to work with low-structured data, but a lot of things are happening under the hood. After rewriting the script written for Glue to PySpark, you may find that you need to manually add things that DynamicFrame did automatically, even without our knowledge.
But why are we mentioning PySpark here if the script can be completely based on the methods provided by DynamicFrame?
It turns out that using only DynamicFrame can be very inefficient when transforming large amounts of data.
While working with Glue, we happened to rewrite transformations from those native to Glue to pure SparkSQL, which significantly accelerated the transformation time and reduced the memory consumption of Spark executors.
You do not have to immediately abandon the possibilities offered by DynamicFrame Glue, but it is worth going down to the Spark DataFrame level if you’re thinking about optimizing your ETLs.
From DynamicFrame, you can jump to DataFrame and back to DynamicFrame at any time, meanwhile using the methods available for DataFrame to cache an intermediate result used later in several places in the script, or evenly distribute data between partitions processed by Spark’s executors.
Then we use the benefits of both worlds and thanks to this you can greatly improve your ETLs and reduce their costs, which is really important when there’s a lack of cheap spots in Glue jobs.
However, there is one big drawback of using Glue: Saving data to partitioned Glue tables was simply problematic.
The data was correctly written to S3, however, the partitions were not added to the Hive metastore of the Glue table, effectively making the data invisible in the table.
Adding partitions while writing data worked with tables with the glueparquet classification, but significantly increased the resources consumed by Job Glue.
In one case, due to major performance issues with one job, we decided (as advised by AWS support) to simply add a crawler to our dataflow, which will add new partitions to the Glue table. I hope that this rather troublesome problem will be resolved by AWS at some point.
Alternatively, you can adopt a different strategy and use Glue only as a place to describe your metadata, that is, use the Glue data directory as a metastore. When working with a data lake, we had to move one of our dataflows to the EMR service, which allowed us to use low-cost spot instances.
Combining the EMR with the Glue catalog was relatively hassle free, but there are some important details worth mentioning here that can be a bit of a problem when pairing Glue with EMR. The first is that Spark’s IAM role needs to be granted database_creator privileges on AWS Lake Formation.
Spark creates a global_temp temporary database for itself, and without proper Lake Formation permissions, it will cause Spark’s job to crash very quickly, resulting in permission-related errors.
The second problem is getting the database list from the Glue directory.
Even if we just want to set the default database to the one we are going to use, Spark first tries to download the list of available databases and the “default” database, whether it has access to it or not. If access is denied then the job throws up an error again.
The last problem we encountered was the need to add the S3 location to the Glue database.
This is an optional parameter, however, it turns out that if it is empty, writing to the Glue tables will fail.
Theoretically, the parameter set in the Glue table should be used as the S3 location. If the database has an S3 location, it is indeed ignored and the S3 location of the table is used for writing. However, if the base S3 location is empty, we get errors.
Athena Problems — Partitioning and a Large Number of Small Files
hanks to Athena, we have access to files from S3 and we can query them using SQL as if they were relational databases. When using Athena, you pay for the amount of data scanned, but this can be optimized with partitions.
From the user level, this looks like additional columns to be polled, but underneath it is a file division using folders. Partitioning can be very useful when using dates — in the UI we see the year, month, day columns.
Below is the directory structure:
– year=2020
- month=04
- day=01
- month=05
– year=2021
With this approach, Athena scans fewer files to get the result, which is cheaper and faster.
One of the problems we encountered while using this tool was the small files that made up our scripts.
During the transformations, PySpark splits the transformations into parallel processes, which in turn create many separate files. Those files should not be too small (around > 128 MB), because each file adds additional time for:
- Opening it
- Listing
- Metadata retrieval
- Loading headers and compression dictionaries
The files cannot be too large either, because then they cannot be read quickly in parallel.
A GitOps Approach to Data Lake Development
In theory, every developer should push their changes as often as possible. If something happens to them, then we are sure that another employee can take over their work.
However, accepting and checking someone’s work is not that simple.
How do we know if their code is working? Can it be released to production without any problems? Did the code undergo testing?
Of course, this can be done manually, but modern systems have CI / CD.
Those scripts run automatically, triggered by code pushed to the repository, which:
- Start the tests.
- Deploy the application.
If any of the steps fail, we know we need to start by fixing it.
With our system, we could build the infrastructure from code, so there was nothing to prevent us from building it from each branch.
Each developer could create their own data lake and test their changes on it.
Unfortunately, many programmers did not clean up their stacks, which meant that we hit the resource limits on the AWS account. We solved this by creating scripts, which wiped out all developer resources every night.
Tests
We had 3 types of tests in our system:
- The first one checked for CloudFormation templates.
- The second one verified contracts.
- The third one checked for data validation at the end of each data flow.
Usually, with unit tests, we check the result of a given function and see whether it agrees with the expected result.
It was not possible to do such tests in this case because the template was generated in one go for the entire code. However, this did not prevent us from writing tests.
By verifying the specific elements in the template, we were able to test for:
- The list of rights assigned to the roles.
- The parameters passed to jobs.
- The service configuration.
The second test checked the contracts where the sole task was to maintain the appropriate schema of tables that were accessed by other teams.
Before creating the tables, we shared these tests in the form of JSONs with the team that mostly used them. We did this to make sure everything they needed was there in a format that would make their job easier.
The last type of tests verified the processed data / tables. They were based on checking previously created requirements for specific data, which in theory should be met by our PySpark scripts.
We checked the following:
- The uniqueness of the rows.
- Whether the columns contain only the expected values (e.g. male, female, undefined).
- The expected date format.
- Whether there were no null values in the given columns.
Who Is This a Good Solution For?
If you need to download data from different sources in different formats and with different frequencies, then a data lake is the right solution.
The increasing number of files, which are counted in TB, can cause problems when we want to store the data on our own servers. Cloud solutions relieve us of this problem and provide security. There are already a few companies that offer solutions and integrations with cloud-service providers.
The choice is very broad, but not everyone can create the entire infrastructure from code.
Architecture created manually by clicking in the console will certainly work, but digging into all of its configurations may be impossible. A data lake is not a solution to all the problems related to big data. This concept is for specific problems and if you use it carelessly, you may encounter a lot more of them.










