
Working on any major project, it is difficult to avoid contact with databases. This knowledge will be useful to every specialist in the IT industry, which is why I have prepared a kind of introduction to graph databases. From the article you will find out which types of databases we can meet most often. I will discuss them according to the increasing complexity of the structure of the data stored.
Key-value databases
These types of databases act like a huge associative array (in Python we call it “dictionary”): we enter a value and label it with a key – a label that allows you to quickly retrieve it later. Due to their simple structure and use, these databases allow for very quick access to data, so they are most often used as a cache. Storing a complex data structure is only possible after serialization. Therefore, it is basically impossible to order the database to perform any operations referring to the stored content. One of the most popular representatives of this group is Redis.
Object / document databases
Document databases can store various data structures while maintaining their arrangement within a given object. At the same time, the database does not impose a specific scheme on the documents, but allows searching and editing values in the fields. However, it may turn out to be problematic to define and watch after the mutual relations between the stored data. Document databases, even if they allow for defining relations between objects, usually do not enforce any data integrity – you have to take care of it yourself. An example of such databases is MongoDB.
Tabular databases (so-called “relational”)
It is currently the most commonly used type of base. The data is arranged in tables with a strictly defined structure and data types. Columns correspond to fields and rows to individual objects. A huge advantage is the strict data integrity mechanisms: If we want to delete an object, the database checks if other objects refer to it and – depending on the “hardness” of the connection and the default way of treating them – it can either delete the related objects, or remove the connections, or prohibit any deletion at all. Due to the important role of relations between objects, these databases are usually called relational. The most popular representatives of this branch are MySQL / MariaDB and PostgreSQL.
Graph databases
After this introduction, we can go on to describe the next stage – graph databases. The idea came from the observation that the relationships between the stored data can be represented in the form of a graph. If anyone has prepared a graphical diagram of the database, you probably remember this kind of pictures:
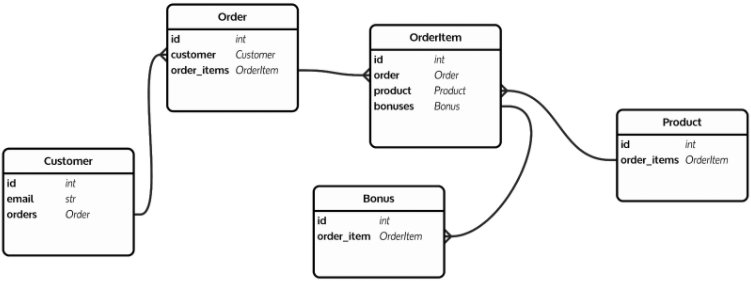
Particular attention should be paid here to many-to-many relationships with intermediate tables, where we could define additional parameters of such a relationship. And since the relations can be parameterized, we can start using graph algorithms to calculate the relationships between the data of interest to us.
Take, for example, such a scenario:
We want to get a list of all users between 21 and 30 years old who made a one-time purchase in our store for more than PLN 100 in the last 30 days, made at least two purchases during this period and at the same time more than half of the products they purchased belonged to some specific category.
Do you understand what I’m getting at? These kinds of queries can be quite laborious for tabular databases. In addition, it may soon turn out that there will be a few more conditions, and the waiting time for a response from the database will no longer be within the critical limit of 300 ms. This approach needs to be changed.
This is where graph databases enter, which have not only full parameterization of relations (we already had an introduction to this in tabular databases), but also the implementation of graph algorithms on the database side.
Key elements
In graph databases we write data using two basic elements: The vertexes (nodes) are the representation of physical objects. We write relations between objects by creating edges. A very important aspect here is the fact that vertices and edges can have any number of attributes, the most important of which is called a label – it determines the type of a given element. It will be easiest to show this with an example.

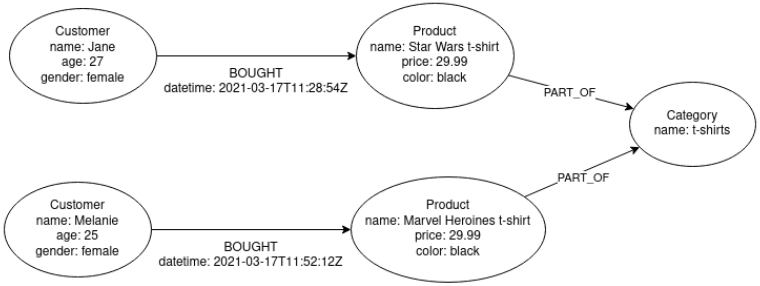
As you can see, we can assign attributes to both vertices and edges.
Plus, it’s easy to see that one of the best things about graph databases is that they’re incredibly intuitive. We can talk about the data structure, draw its diagram and then 1: 1 translate it into the database into specific objects.
Benefits
- intuitiveness – I mentioned this a moment ago. The ability to represent data in a natural way for the (average) human mind. Usually, when analyzing a problem, we think with graphs without even being aware of it.
- no migration – because the data does not have a rigidly imposed structure, we can easily supplement objects with new data. Queries for new attributes will simply skip objects that do not have attributes.
- ease of querying – here it is often a question of the selected query language, although in the case of declarative languages like Cypher or SparQL, we can write a query in a few lines, which in SQL (also declarative, but on a different layer) would take several dozen lines.
- speed – thanks to specific implementation and special indexing, in many cases accelerations of up to five orders of magnitude (from minutes to milliseconds) can be achieved.
Usage
Now let’s move on to the most popular applications. It is obvious that the best field for using such databases are problems that can be described as “strongly graph-like”. But how to identify them? Let us try the path “indirectly” – let us reject topics for which the graph database is not the best fit.
Imagine we are running a cafe. We have a list of products with a price list and save the transactions. If we are interested in information on turnover or the most popular products, the graph database is not a good choice – it is better to leave information aggregation (summing up, calculating averages, etc.) to the tabular database. However, if we look a little deeper, we find issues with a typical graph lineage: which products are most often bought together? What hours and / or days does the product sell best?
In fact, the best scenarios for using graph databases are:
- recommendation systems – the more profiled the user, the more effectively we can recommend other products,
- logistics – optimally deliver parcels, planning trips, flights, etc.,
- management – what are the relationships between the components of the infrastructure? which element of our infrastructure is the most critical?
- fraud detection – if we have funds from one institution to many different places, but ultimately controlled by another institution, it may be worth taking a closer look at whether money laundering laws are violated.
Popular implementations
- Apache TinkerPop – has established one of the graph database standards and is the benchmark for many related databases, such as AWS Neptune or Azure Cosmos DB. In addition to the database engine itself, it provides advanced data analysis mechanisms. The language used in these databases is Gremlin.
- Neo4j – one of the most popular database engines. The language is Cypher.










