Odkąd Google Chrome ogłosił, że przestanie obsługiwać ciasteczka stron trzecich (third-party cookies), wydawcy, agencje, firmy AdTech i reklamodawcy zastanawiają się, jaka będzie przyszłość reklamy online.
Jednak wyłączenie obsługi ciasteczek nie rysuje jeszcze całego kontekstu sprawy. Aby zrozumieć, w czym tkwi problem, potrzebujemy przyjrzeć się mechanizmom takim jak synchronizacja ciasteczek, identyfikacja czy targetowanie reklam. Na koniec, powinniśmy także poznać rozwiązanie Privacy Sandbox, które ma zastąpić ciasteczka.
Rola ciasteczek stron trzecich w reklamie internetowej
Przez prawie dwadzieścia lat ciasteczka stron trzecich (third-party cookies) napędzały kilka ważnych procesów reklamowych:
- identyfikowały użytkownika na różnych stronach www (pod warunkiem, że korzysta z tej samej przeglądarki internetowej),
- pozwalały prowadzić kampanie targetowane i retargetingowe,
- pozwalały aktywizować grupy odbiorców na platformach DMP i DSP
- pozwalały mierzyć skuteczność kampanii reklamowych.
Jednak samo tworzenie plików nie sprawi, że powyższe procesy będą działać. Systemy tworzą swoje ciasteczka, a każde z nich zawiera informację o powiązaniu z systemem partnerskim, np. DSP 1 jest związane z DMP 3. Aby procesy zadziałały, dostawcy współdzielą ciasteczka, co nazywamy synchronizacją ciasteczek (cookie syncing).
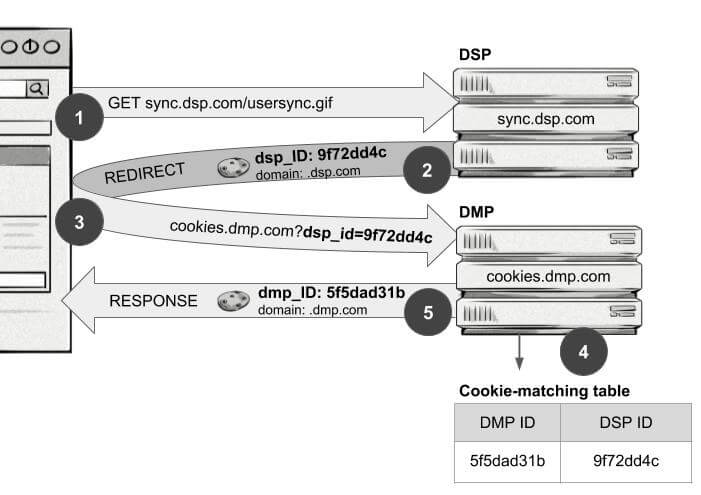
Co to jest synchronizacja ciasteczek i jakie ma znaczenie?
Pliki cookies są tworzone dla konkretnej domeny. To znaczy, że informacje w nich zapisane, może odczytać tylko domena, która je utworzyła. Innymi słowy dsp.com nie odczyta ciasteczka utworzonego przez dmp.com.
Takie ograniczenie blokuje firmom AdTech możliwość rozpoznania użytkownika, który odwiedza różne strony www.
Jak więc ssp1.com może poinformować dsp1.com, że użytkownik w strony Publisher.com pasuje do grupy docelowej? Właśnie w tym celu wykorzystuje się synchronizację ciasteczek.
Synchronizacja ciasteczek dopasowuje pliki cookie utworzone przez jedną platformę AdTech do innej. Ale ponieważ identyfikatory plików cookie są różne dla różnych platform, ciasteczka są synchronizowane za pomocą specjalnych tabeli.
Do synchronizacji ciasteczek wykorzystuje się tzw. piggybacking. Piggybacking polega na tym, że jeden dostawca AdTech (np. DMP) ładuje piksel innego dostawcy AdTech.
Gdy jedna platforma tworzy ciasteczko, wywołuje proces tworzenia ciasteczka innej platformy. Dodatkowo przy wywołaniu podaje ID swojego ciasteczka i mogą się zsynchronizować.
Dzięki temu dsp.com i dmp.com mogą “rozmawiać” o tym samym użytkowniku. Piggybacking umożliwia reklamodawcom identyfikację członków ich grup docelowych na różnych stronach www.
Teraz, gdy wiemy, jaką rolę w reklamie online odgrywają ciasteczka stron trzecich i ich synchronizacja, przyjrzyjmy się dostępności ciasteczek.
Mniejsza dostępność ciasteczek stron trzecich
Dostępność ciasteczek stron trzecich zaczęła spadać, gdy w połowie 2000 roku wprowadzono ad blokery.
Większość ad blockerów uniemożliwia ładowanie tagów reklamowych (np. fragmentów kodu JavaScript) na stronie internetowej. A gdy tagi nie ładują się, nie można tworzyć ciasteczek stron trzecich.
RODO i inne akty prawne odnoszące się do prywatności w przeglądarkach, mają znaczący wpływ na ograniczenie ciasteczek stron trzecich. Warto zwrócić uwagę, że popularne przeglądarki Safari i Firefox blokują ciasteczka domyślnie, nie oferując przy tym reklamodawcom żadnej alternatywy.
Pewne zmiany w obsłudze ciasteczek stron trzecich wprowadził także Google Chrome. Google wymaga od twórców stron www i firm AdTechowych oznaczania plików cookie stron trzecich za pomocą parametru SameSite=None. Ma to ułatwiać użytkownikom blokowanie i usuwanie niechcianych plików cookie stron trzecich.
We wtorek 14 stycznia 2020 r. Google Chrome ogłosił, że w ciągu najbliższych dwóch lat całkowicie przestanie obsługiwać pliki cookie stron trzecich. Pół roku później, 24 czerwca 2021 r. ogłoszono przedłużenie tego terminu o 2 lata. Aktualnie przewidywany termin to połowa 2023 r. Dowiedz się więcej tutaj.
Jako że duża część przychodów firmy Alphabet (spółki macierzystej Google) pochodzi z reklam, Google Chrome nigdy nie postąpi jak Safari czy Firefox, zostawiając reklamodawców bez alternatywy dla ciasteczek stron trzecich. A tą alternatywą jest Privacy Sandbox.
Co to jest Privacy Sandbox?
Privacy Sandbox to zestaw otwartych standardów, które mają dobrze chronić prywatność użytkowników i utrzymać sieci reklamowe. Google po raz pierwszy ogłosił rozpoczęcie prac nad Privacy Sandbox 22 sierpnia 2019 r.
Podobnie jak w przypadku innych piaskownic używanych w branży bezpieczeństwa komputerowego, Privacy Sandbox będzie przeprowadzać procesy reklamowe w zamkniętym środowisku.
Co ma się po kolei wydarzyć podczas wprowadzania Privacy Sandbox?
- Zastąpienie procesów śledzenia użytkownika na wielu stronach — tych, które są obecnie obsługiwane przez ciasteczka stron trzecich.
- Wycofanie plików cookie stron trzecich. Z pomocą atrybutu SameSite ma nastąpić oddzielenie ciasteczek stron trzecich (third-party cookies) od ciasteczek stron pierwszych (first-party cookies), a następnie wyłączenie wsparcia dla ciasteczek stron trzecich.
- Wprowadzenie takich rozwiązań, które będą zapobiegać lub łagodzić skutki obchodzenia nowych wytycznych dla prywatności. Przykładem obejścia może być fingerprinting. Narzędzie do tworzenia fingerprintów odpytują stronę www o wiele zmiennych (np. wielkość i rozdzielczość ekranu, kartę graficzną, strefę czasową, listę obsługiwanych czcionek itp.). Zestaw tych informacji wykorzystuje się do identyfikacji danego użytkownika lub jego urządzenia.
Skupimy się jednak na pierwszym punkcie, ponieważ będzie miał największy wpływ na branżę reklamy internetowej.
Standardy dla Privacy Sandbox są wypracowywane na arenie grupy biznesowej W3C Improving Web Advertising Business Group. Grupa składa się z firm AdTech, agencji, wydawnictw, zespołów Google Chrome i działów reklamy Google. Privacy Sandbox ma reprezentować zupełnie nowy sposób działania reklam online.
Poniżej opiszemy jak aktualnie działają procesy reklamowe w niezależnych firmach AdTech. Pokażemy też jak prawdopodobnie te procesy będą działać w przyszłości, kiedy rozwiązanie Privacy Sandbox zostanie już uruchomione. Poniższe diagramy mają na celu przedstawienie ogólnego obrazu proponowanych zmian w Chromie.
Warto również zauważyć, że W3C omawia wiele zgłoszonych do niej pomysłów i propozycji. Poniżej opiszemy najważniejsz, ale pełną listę możesz znaleźć tutaj.
Jak AdTech działa teraz vs jak będzie działać Privacy Sandbox?
Przyjrzymy się trzem procesom w reklamie online:
- identyfikacja,
- targetowanie i kupowanie przestrzeni reklamowej,
- mierzenie skuteczności i raportowanie wyników.
Identyfikacja
AdTech teraz
Identyfikowanie użytkownika w większości przypadków odbywa się za pomocą ciasteczek stron trzecich.
Spójrz, jak to działają procesy identyfikacyjne.
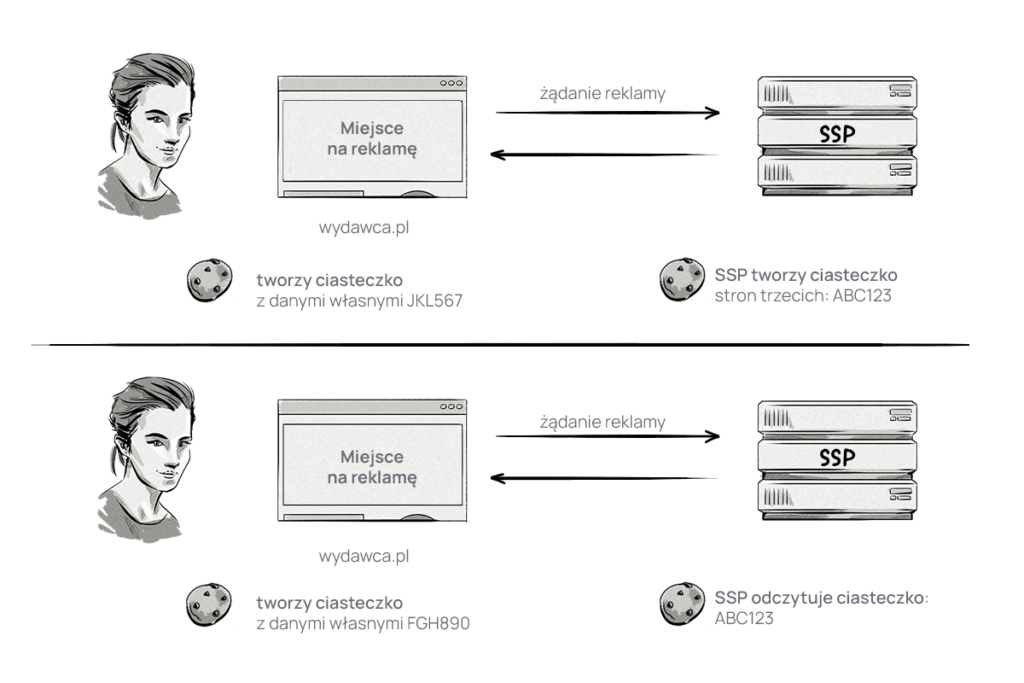
Dostawca AdTech, który utworzył ciasteczko strony trzeciej w przeglądarce użytkownika, może je odczytać, gdy użytkownik odwiedza inną witrynę, pod warunkiem, że jego kod zostanie załadowany na stronie, która została albo dodana bezpośrednio przez wydawcę, albo poprzez zastosowanie kodu innej firmy AdTech.
Gdy ciasteczka stron trzecich przestaną działać, firmy AdTechowe poszukają innych sposobów identyfikacji użytkowników. Rozwiązania te jednak będą mieć mniejsze możliwości niż ciasteczka. W sekcji Możliwe rozwiązania, piszemy o tym więcej.
Privacy Sandbox
Celem Privacy Sandbox jest zapewnienie środowiska reklamowego, które nie opiera się na identyfikacji użytkowników 1:1. Privacy Sandbox nie identyfikuje poszczególnych użytkowników.
To ogromna zmiana, do której wydawcy, marki, agencje i dostawcy AdTech, którzy zbudowali swoje firmy wokół identyfikacji osób w sieci, będą musieli się przyzwyczaić.
Chociaż wielu dostawców AdTech korzysta np. z własnych plików cookie, nie można wykluczyć, że Chrome ograniczy takie praktyki, podobnie jak zrobiła to przeglądarka Safari, wprowadzając Intelligent Tracking Prevention (ITP).
Na stronie poświęconej Privacy Sandbox, można znaleźć dowody na popracie tej tezy (ważny tekst pogrubiony):
Misją projektu Privacy Sandbox jest „stworzenie dobrze prosperującego ekosystemu internetowego, który szanuje użytkowników i domyślnie jest prywatny”. W Tej misji głównym wyzwaniem do pokonania jest wszechobecne śledzenie między witrynami, które stało się normą i na bazie którego sieć częściowo dostarcza treść i zarabia na niej. Gdy projekt wejdzie w życie, będziemy nakładać coraz więcej ograniczeń na korzystanie z ciasteczek stron trzecich, które są obecnie najpowszechniejszym mechanizmem śledzenia między witrynami i ostatecznie przestaniemy je wspierać. Równolegle będziemy agresywnie zwalczać obecne techniki śledzenia między witrynami nie oparte na plikach cookie, takie jak fingerprinting, inspekcja pamięci podręcznej, link decoration, śledzenie sieci i łączenie informacji umożliwiające identyfikację osoby (PII). Ponieważ usuwamy możliwość śledzenia użytkownika w wielu witrynach za pomocą ciasteczek, musimy upewnić się, że deweloperzy mają wszystkie potrzebne narzędzia do wdrożenia nowych standardów, zamiast próbować śledzić użytkowników w inny sposób.
Ostatnie zdanie sugeruje, że wszelkie alternatywy śledzenia w wielu witrynach (próby obejścia) tworzone przez firmy AdTech, będą ograniczone lub blokowane przez Chrome.
Targetowanie reklam i kupowanie przestrzeni reklamowej
Niezależna technologia reklamowa
Firmy AdTechowe oferują różne metody targetowania, przy czym dwie najpopularniejsze to metody to targetowanie kontekstowe i targetowanie behawioralne.
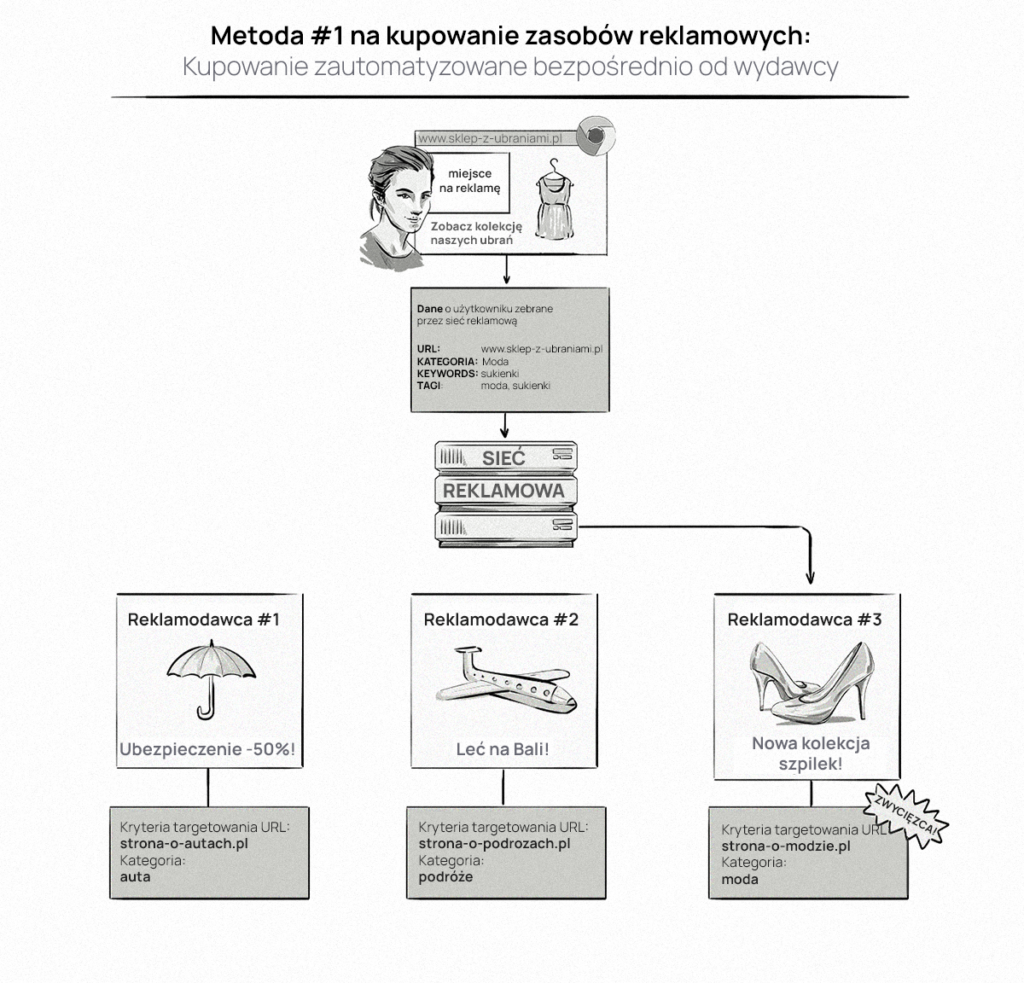
Targetowanie kontekstowe wykorzystuje kontekst strony do określenia, które reklamy mają być wyświetlane użytkownikowi. W tym celu web crawlery oraz żądania nagłówków HTTP agentów użytkowników gromadzą potrzebne informacje.
Większość kontekstowych kampanii reklamowych jest realizowanych przez sieci reklamowe podczas kupowania przestrzeni reklamowych, czyli podczas programmatic direct.
Targetowanie behawioralne wykorzystuje dane znane o użytkownikach, takie jak odwiedzane przez nich witryny czy kupione produkty, aby określić, które reklamy mają być wyświetlane. Dane te zbierają firmy AdTech i platformy danych (np. DMP), aby dodać je do profili użytkowników.
Gdy reklamodawcy mają w swojej bazie wiele profili, grupują je (tworzą grupy odbiorców) i targetują na nie kampanie reklamowe.
Retargeting także wykorzystuje dostępne informacje o użytkownikach, jednak wyświetla reklamy tym użytkownikom, którzy weszli w interakcję z marką, np. oglądali produkty w witrynie.
Reklamodawcy prowadzą kampanie behawioralne i retargetingowe głównie przez licytację w czasie rzeczywistym (real-time bidding, RTB).
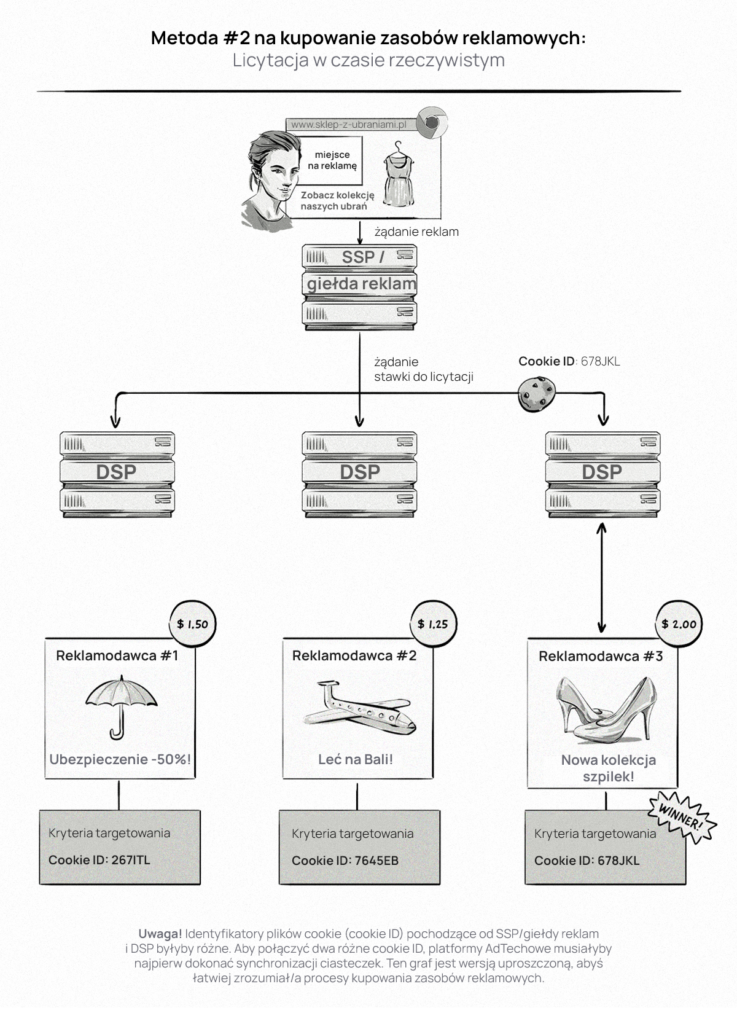
Określanie stawek na licytacjach RTB rozpoczyna się po załadowaniu kodu dostawcy usług internetowych (fragment kodu JavaScript) w witrynie wydawcy. Platforma zakupu reklam (SSP) następnie wysyła zapytanie ofertowe do wielu platform sprzedaży reklam (DSP).
SSP może odpytywać o:
- typ, rozmiar i miejsce wyświetlenia reklamy,
- kategorie treści wg IAB (np. motoryzacja, moda),
- informacje o urządzeniu (typ urządzenia, system operacyjny, marka i model urządzenia oraz wersja urządzenia),
- identyfikator pliku cookie, który służy do rozpoznawania użytkowników w różnych witrynach internetowych, umożliwiając reklamodawcom identyfikację osób w grupach docelowych.
Jeśli informacje zawarte w zapytaniu o stawkę odpowiadają kryteriom docelowym, DSP odsyła odpowiedź na ofertę. DSP, które otrzymało najwyższą stawkę wygrywa aukcję, a reklama reklamodawcy jest wyświetlana użytkownikowi.
RTB w dużym stopniu opiera się na ciasteczkach stron trzecich i ich synchronizacji, aby móc identyfikować i śledzić użytkowników w różnych witrynach internetowych. Aby proces nadal działał bez ciasteczek stron trzecich, firmy AdTech będą musiały użyć innego identyfikatora. Więcej na ten temat dowiesz się w sekcji Możliwe rozwiązania.
Podsumowując, reklama kontekstowa może być prowadzona bez wiedzy o użytkowniku — np. reklamodawca może wyświetlić reklamę roweru górskiego na stronie internetowej poświęconej kolarstwu górskiemu. Z kolei targetowanie behawioralne i retargetowanie wykorzystuje dane o zainteresowaniach i zachowaniu użytkownika, takie jak odwiedzone strony internetowe i zakupione produkty.
Ale czy targetowanie behawioralne zapewnia wydawcom większe przychody z reklam w porównaniu z targetowanie kontekstowym?
Badanie przeprowadzone w 2019 r. przez Veronicę Marottę, Vibhanshu Abhisheka i Alessandro Acquisti pokazało, że obecność ciasteczek w witrynie dużego wydawcy przekłada się na wzrost CPM o 4% dla wydawców.
Raport ten sugeruje, że targetowanie behawioralne nie jest dużym źródłem przychodów wydawców, co stoi w sprzeczności z twierdzeniami wielu firm AdTechowych. Jednak pamiętajmy, że diabeł tkwi w szczegółach i w tym przypadku wiele ważnych czynników mogło nie zostać uwzględnionych.
Niedawno zespół Google Ad Manager przeprowadził eksperyment, w którym zablokował dostęp do ciasteczek niewielkiej części użytkowników, aby sprawdzić, czy przychody z reklam wydawców spadną, gdy tej ciasteczek nie będzie.
Zespół Google odkrył, że po wyłączeniu ciasteczek przychody z reklam spadły o 52% w przypadku 500 największych światowych wydawców, przy czym mediana spadku przypadająca na wydawcę wyniosła 64%.
Eksperyment podkreśla wartość spersonalizowanej i ukierunkowanej reklamy.
Privacy Sandbox
Targetowanie reklam w Privacy Sandbox będzie dość podobne do targetowania dzisiaj, z kilkoma drobnymi różnicami.
Metoda targetowania reklam nr 1: Targetowanie kontekstowe i targetowanie po własnych danych
Jako pierwszą metodę targetowania Privacy Sandbox proponuje użycie targetowania kontekstowego i targetowania na własne dane.
Dzięki tej metodzie użytkownikom będą wyświetlane reklamy dopasowane do kontekstu odwiedzanej strony, podobnie jak obecnie działa reklama kontekstowa.
Jedyna różnica polega na tym, że Privacy Sandbox będzie informować platformy AdTech o kontekście strony i zachowaniu użytkownika w witrynie i wykluczy z procesu np. web crawlery.
Metoda targetowania reklam nr 2 (odrzucona): Targetowania oparte na zainteresowaniach za pomocą FLoC
Oryginalna koncepcja Google dotycząca targetowania opartego na zainteresowaniach – Federated Learning of Cohorts (FLoC), polegała na dodawaniu użytkowników do grupy (tzw. kohorty) na podstawie odwiedzanych przez nich witryn. Reklamodawcy byliby wówczas w stanie kierować do nich reklamy na podstawie kohort, do których należą, a nie na poziomie indywidualnym.
W skrócie, FLoC miał działać tak:
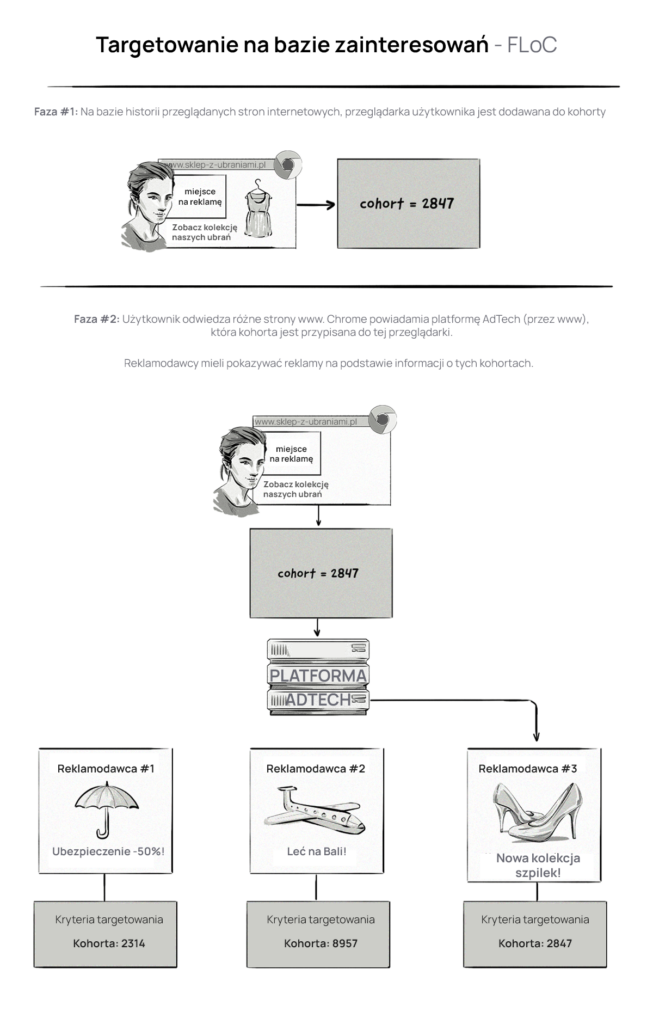
AKTUALIZACJA: 25 stycznia 2022 r. Google ogłosił, że wycofuje projekt FLoC i zastępuje go nową inicjatywą — Topics API. O Topics API piszemy poniżej.
Targetowanie odbywałoby się na poziomie kohorty (kategorii zainteresowań), a dane byłyby przetwarzane na urządzeniu, co oznacza, że żadne dane użytkownika nie byłyby przekazywane do platform AdTech – oprócz nazwy kohorty, do której użytkownik został przypisany. FLoC wyraźnie różniłby się od targetowania przez ciasteczka stron trzecich
Raport specjalny W ExchangeWire Industry Review opublikowaliśmy raport specjalny nt. FLoC pt. Reframing the Future. Raport jest dostępny tutaj na stronie 9.
25 stycznia 2021 r. Google Chrome ogłosił, publiczne udostępnienie FLoC API do testowania w marcu 2021 r. Testowanie FLoC w Google Ads rozpoczęło się w drugim kwartale 2021 r. Po testach Google odrzuciło projekt FLoC.
Na podstawie testów FLoC-a można było wnioskować, że reklamodawcy mogliby spodziewać się co najmniej 95% konwersji na wydanego dolara w porównaniu z reklamami opartymi o ciasteczka.
Nie wszyscy jednak wierzyli, że FLoC chroni prywatność na odpowiednim poziomie.
Electronic Frontier Foundation (EFF) wyraziła szereg obaw dotyczących rzeczywistej skuteczności FLoC-a w kwestii wspierania prywatności użytkowników.
EFF stwierdził, że same kohorty ułatwiłyby firmom tworzenie tzw. fingerprints (elektronicznych śladów urządzeń użytkowników). To z kolei prowadziłoby do identyfikacji konkretnej osoby i uzyskiwania informacje na jej temat.
Chociaż jest w tym trochę prawdy, Google podjął odpowiednie środki zapobiegawcze i deklaruje, że w przyszłości będzie kłaść jeszcze większy nacisk na ochronę prywatności użytkowników.
Google nie sprecyzował też, jakie kohorty miałyby powstać, choć z góry wiadomym było, że te związane z rasą, seksualnością czy poglądami politycznymi by nie zaistniały. Największą zagwozdką było to, że kohorty miały być tworzone przez maszynę, a nie osobę, co utrudniłoby identyfikację i zablokowanie wrażliwych kategorii.
Topics API
25 stycznia 2022 r. Google ogłosił, że wycofa FLoC i zastąpi go nową inicjatywą — Topics API.
Ogłoszenie nie było całkowicie niespodzianką, bo Google przedstawił pomysł zmiany FLoC-a na Topics API w lipcu 2021 roku.
Google powiedziało, że jednym z głównych powodów decyzji o odejściu od targetowania opartego na zainteresowaniach na rzecz targetowania tematycznego był feedback na temat FLoC-a. Mimo że FLoC został zaprojektowany jako alternatywa dla śledzenia użytkowników z wykorzystaniem ciasteczek, obawy dotyczyły właśnie prywatności.
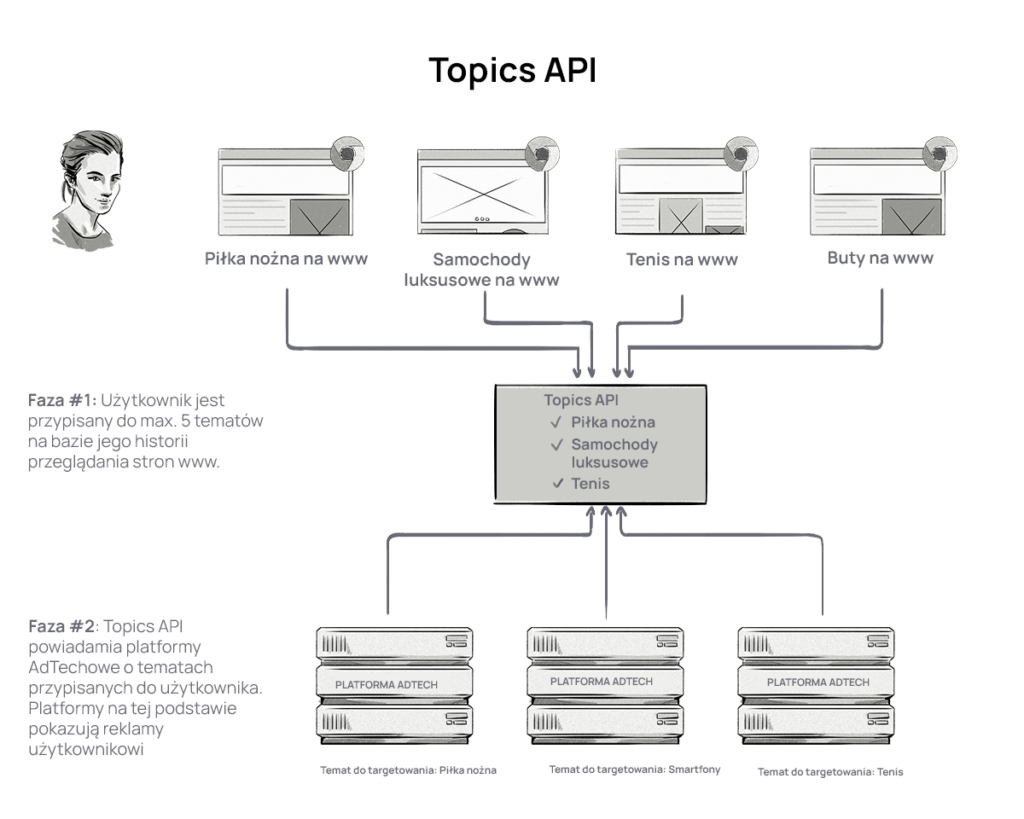
Najważniejsze informacje o Topics API i różnicach pomiędzy Topics API a FLoC:
- FLoC miał przypisywać użytkowników do kohort; Topics API wygeneruje do 5 tematów, które aktualnie interesują użytkownika – na podstawie odwiedzanych przez niego witryn.
- Tematy te (topics) otrzymają nazwy, które mają być zrozumiałe dla ludzi, np. sport, luksusowe samochody, muzyka punk rockowa itp. W przypadku FLoC każda kohorta miała mieć swój identyfikator (ID), który nie dawałby firmom informacji o tym, czym użytkownicy byli zainteresowani, ale pozwoliłby algorytmowi FLoC na wyświetlanie spersonalizowanych reklam.
- Podobnie jak w przypadku FLoC, tylko strony, które zaimplementowały Topics API, będą gromadzić informacje o zainteresowaniach użytkowników i udostępniać je reklamodawcom oraz firmom AdTech.
- Standard Topics API wybierze 3 konkretne tematy dla użytkownika, który odwiedza witrynę uczestniczącą w programie Topics API. Te tematy reklamodawcy mogą wykorzystać do targetowania
- Tematy powiązane z użytkownikiem pozostaną aktywne tylko przez 3 tygodnie; po tym czasie zostaną wygenerowane nowe tematy.
- Możliwe jest łączenie tematów, np. targetowanie na użytkownika, który interesuje się samochodami sportowymi i luksusowymi.
- Podobnie jak FLoC, Topics API będzie przetwarzał informacje na urządzeniu użytkownika. Dane zebrane w celu uruchomienia Topics API nie będą przesyłane na serwery Google.
- Żadne informacje o odwiedzanych przez użytkownika witrynach nie będą udostępniane.
- W przyszłości użytkownicy będą mogli zobaczyć, z jakimi tematami są powiązani. Będą też mieli kontrolę nad tymi tematami.
- Google chciałoby, aby projektem Topics API zarządzała organizacja zewnętrzna, taka jak IAB.
- W przeciwieństwie do FLoC-a, który został wycofany z testów w Europie z powodu problemów związanych ze zgodnością z RODO, Topics API ma być wdrożenie na całym świecie.
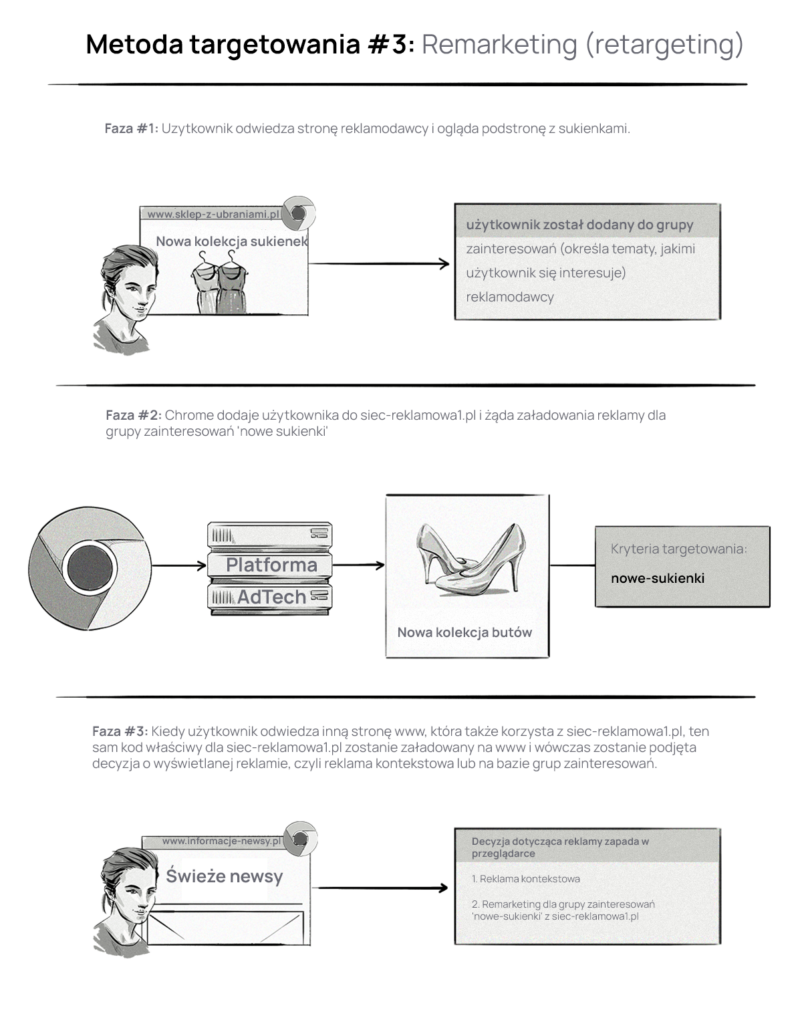
Metoda targetowania reklam nr 3: Remarketing (inaczej retargeting)
Metoda remarketingu (inaczej retargeting) jest podobna do metody targetowania opartego na zainteresowaniach (interest-based targeting). Różnica uwidacznia się w procesie podejmowania decyzji o wyświetlanej reklamie:
- Dzięki pierwszej metodzie (interest-based targeting), reklamodawcy mogą dotrzeć do użytkowników przynależących do konkretnych grup zainteresowań.
- Z kolei dzięki remarketingowi, przeglądarka wyśle do platformy AdTech dwa żądania reklam — jedno zawierające informacje kontekstowe, a drugie odwołujące się do grupy zainteresowań, do której należy użytkownik.
Z poniższej ilustracji dowiesz się jak działa retargeting w praktyce.
TURTLEDOVE
Proces, którego Privacy Sandbox używa do remarketingu to Two Uncorrelated Requests, Then Locally-Executed Decision On Victory – TURTLEDOVE. Można to przetłumaczyć jako dwa żądania reklamy (two requests), które nie są ze sobą skorelowane (uncorrelated), gdzie decyzja o wyświetleniu (decision on victory) jest podejmowana w lokalnym środowisku użytkownika (locally-executed).
Jak to działa?
Platforma AdTech nie wie, że dwa żądania reklamy pochodzą od tego samego użytkownika – stąd w nazwie „dwa nieskorelowane żądania”. Czas połączenia dwóch żądań o reklamę jest łączony, a przez to platformy AdTech nie są w stanie zidentyfikować użytkowników.
Interesujące w tym podejściu jest to, że decyzje dotyczące wyświetlania reklam, a także mechanika aukcji będą prowadzone na lokalnym urządzeniu użytkownika (czyli w jego przeglądarce internetowej), a nie przez platformy AdTech. TURTLEDOVE zakłada, że w przeglądarce nie ma miejsca na ograniczenie liczby wyświetleń (frequency capping), testy A/B czy optymalizację.
SPARROW
Criteo, francuska firma z branży AdTech, w maju 2020 r. opublikowała swoją alternatywną propozcyję dla TURTLEDOVE od Chrome.
Criteo proponuje SPARROW – Secure Private Advertising Remotely Run On Webserver.
SPARROW przenosi wszystkie procesy reklamowe na dedykowany webserwer, czyli na gatekeepera. DSP i SSP mogą dodawać modele licytacji i logikę aukcji do gatekeepera.
Ale chociaż SPARROW to krok we właściwym kierunku, propozycja ma szereg wyzwań do pokonania, zanim będzie można w ogóle rozważyć jej przyjęcie.
1. Które firmy będą pełnić funkcję gatekeepeera?
Criteo sugeruje, że może to być firma AdTech, która już jest zaangażowana w procesy reklamowe, np. SSP, ale gatekeeper musiałby być niezależny i nie mieć żadnych interesów handlowych w aukcjach.
Wykluczyłoby to każdą firmę AdTech na rynku. Organizacja taka jak IAB wydaje się być odpowiedniejszym wyborem.
2. Jak rozwiązane zostaną kwestie prywatności?
TURTLEDOVE kładzie nacisk na to, aby nie gromadzić żadnych danych na poziomie użytkownika i uniemożliwiać firmom identyfikowanie osób. Stosuje w tym celu pięciogwiazdkową skalę, oceniając zakres prywatności.
SPARROW zapewniłby podobne środki ochrony prywatności. Istnieje jednak prawdopodobieństwo, że dane zebrane przez gatekeepera mogłyby zostać wykorzystane do identyfikacji osób i potencjalnie prowadzić do sprzedaży danych użytkowników.
Aby uniknąć takich sytuacji, gatekeeper miałby:
- poddawać się okresowemu audytowi ze strony Organów Ochrony Danych (Data Protection Authorities, DPA),
- określić praktyki zarządzania danymi (np. sposób przechowywania danych)
- oraz zapewnić publiczne API.
Jednak te rozwiązania nadal nie spełniają wymagań ochrony prywatności Chrome. Grupa biznesowa W3C aktualnie dyskutuje o zaletach i wadach SPARROW.
Dovekey
We wrześniu 2020 r. zespoły Google pokazały propozycję Dovekey, czyli kontynuację projektu SPARROW.
Dovekey miał być ulepszoną wersją SPARROW. Ta propozycja wprowadza zewnętrzny serwer KEY-value (KV), który ma być używany do obsługi procesów licytacji i aukcji TURTLEDOVE.
Google wyjaśnia Dovekey w ten sposób:
Dovekey obsługuje wiele podobnych przypadków co SPARROW, jednocześnie lepiej radzi sobie z kilkoma wyzwaniami: - Dovekey zmniejsza potrzebę ponownego wdrożania logiki na serwerze zewnętrznym; serwer KV będzie cachował wyniki istniejącej już logiki stworzonej dla licytacji i kontroli. - Dovekey wykorzystuje proces audytu open-source, aby ustalić wiarygodność serwera; serwer KV obsłuży tylko dobrze zdefiniowaną, ograniczoną funkcjonalność. - Dovekey zagwarantuje prywatność użytkownika - serwer KV może być wdrożony w sposób prywatny lub półprywatny. Główną ideą Dovekey jest to, że dostajemy większość korzyści z biddowania SPARROW, nawet jeśli Gatekeeper działa jako prosta tabela – zaufany serwer Key-Value (KV), który otrzymuje klucz (sygnał kontekstowy + grupa zainteresowania) i zwraca wartość (bid).
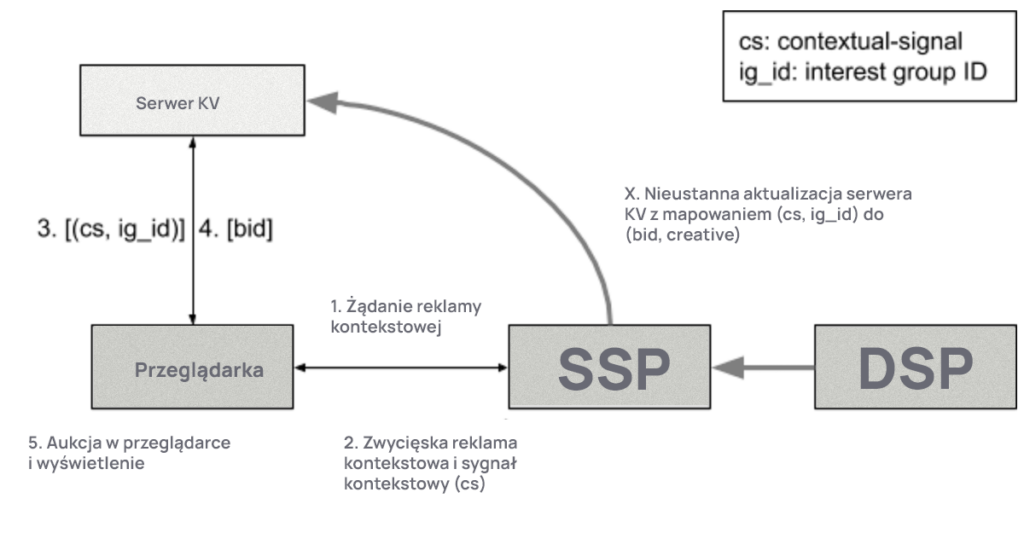
- Przeglądarka wysyła żądanie reklamy kontekstowej – jak w propozycji TURTLEDOVE.
- SSP zwraca wybrane (zwycięskie) reklamy kontekstowe wraz z sygnałami kontekstowymi oddzielnymi dla SSP i DSP. Ostateczny sygnał kontekstowy jest tworzony jako łańcuch sygnałów pochodzących z DSP i SSP.
- Przeglądarka konstruuje klucz, łącząc sygnał kontekstowy i identyfikator grupy zainteresowań (ig_id) i wysyła te klucze w żądaniu do serwera KV.
- Serwer KV zwraca wszystkie bidy powiązane z żądaniami. (*)
- Przeglądarka prowadzi prostą aukcję między kandydatami grup zainteresowań z serwera KV a zwycięską reklamą kontekstową. (*)
- Jeśli wygra reklama kontekstowa, przeglądarka może kontynuować renderowanie reklam.
- Jeśli wygra reklama powiązana z grupą zainteresowań, przeglądarka może wysłać kolejne żądanie do serwera KV, aby pobrać kreatyw; kreatyw może też być pobrany z wyprzedzeniem za pomocą żądania grupy zainteresowań, jak w propozycji TURTLEDOVE
(*) Kroki 4 i 5 są potrzebne, zakładając, że serwer KV może wykonywać tylko wyszukiwanie. Możliwe jest również, że serwer KV przeprowadzi ostateczną aukcję, w której to przypadku należy zwrócić tylko zwycięskie bidy i kreatywy.
Google sugeruje, że Dovekey może obsługiwać:
- Zarządzanie budżetem
- Uwzględnianie sygnałów po stronie przeglądarki
- Dodawanie nowych zasobów reklamowych
- Testy A/B
- Wykrywanie oszustw i zapewnianie bezpieczeństwa
- Reklamy na poziomie produktu
Dovekey z pewnością wydaje się być ulepszeniem, a fakt, że może obejmować procesy takie jak zarządzanie budżetem, testy A/B i wykrywanie oszustw, może oznaczać, że zostanie dobrze przyjęty przez członków W3C.
Jednak wciąż pozostaje kilka otwartych pytań:
- Kto będzie hostem serwera KV?
- Czy jakakolwiek firma AdTech będzie w stanie skonfigurować serwer KV, czy spotka się z jakimiś ograniczeniami?
- W jaki sposób serwer/y KV będą nadzorowane (aby uniknąć gromadzenia danych na poziomie użytkownika)? W tym celu przewiduje się użycie protokołów kryptograficznych i systemu wyszukiwania informacji prywatnych (Private Information Retrival, PIR) na pojedynczym serwerze.
Mimo tych wątpliwości, wszystko wskazuje na to, że propozycje idą w dobrym kierunku.
PARROT
Firma Magnite (dawniej Rubicon Project) opublikowała niedawno propozycję o nazwie Publisher Auction Responsibility Retention Revision of TurtleDove – PARROT.
Projekt czerpie z podejścia do prywatności TURTLEDOVE, ale przekazuje kontrolę nad decyzjami dotyczącymi aukcji w ręce wydawców dzięki wykorzystaniu Fenced Frames (to kolejna propozycja zespołu Google Chrome).
TERN
TURTLEDOVE Enhancements with Reduced Networking (TERN) to propozycja firmy NextRoll.
TERN ulepsza mechanizmy TURTLEDOVE na podstawie informacji zebranych z wątków i repozytoriów GitHub.
Fenced Frames
Fenced Frames to propozycja inżynierów Google. Ładowanie zawartości ramek z reklamami jest tu odizolowane od strony, na której te ramki są osadzone. Fenced Frames API tworzy silną granicę między reklamą i zawartośćią strony, aby uniemożliwić reklamodawcą identyfikację użytkowników i śledzić ich między witrynami.
API Fenced Frames byłby używany do komunikacji ze standardami Privacy Sandbox, takimi jak TURTLEDOVE, aby wyświetlać reklamy oparte na zainteresowaniach.
FLEDGE
Zespół Google Chrome zaproponował First „Locally Executed Decision over Groups Experiment” (FLEDGE), prototyp dla procesów wyświetlania reklam w TURTLEDOVE. FLEDGE korzystał z propozycji firm wymienionych powyżej, jednak projekt został odrzucony na etapie testów.
Pomiar i raportowanie reklam
AdTech teraz
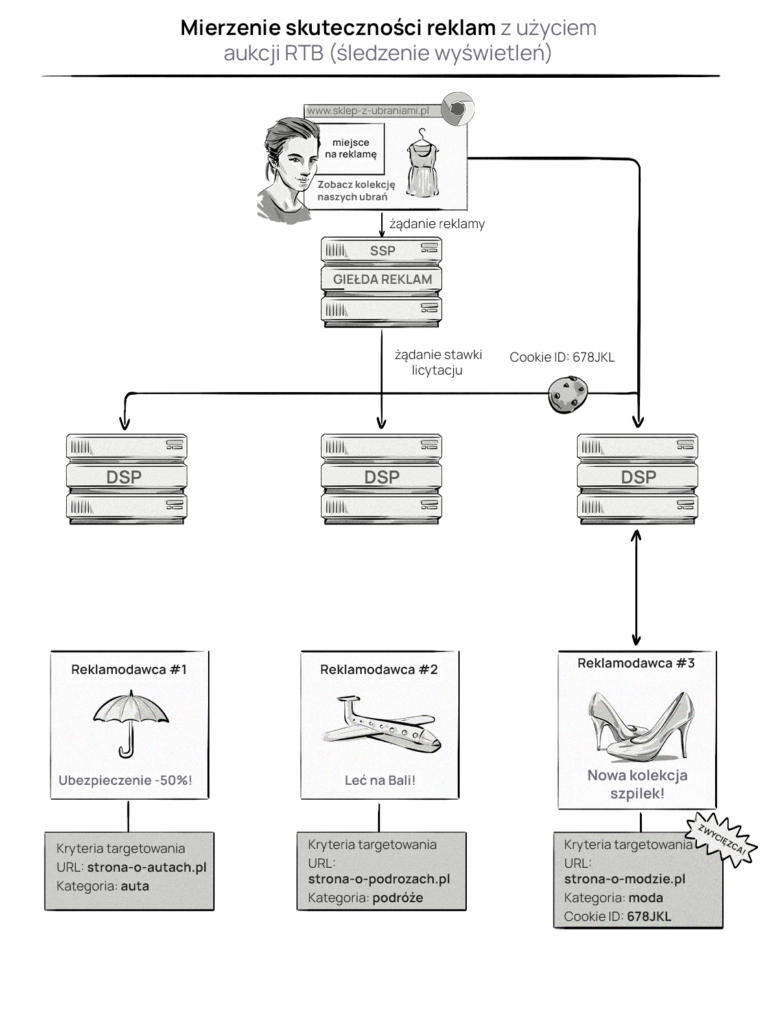
Firmy AdTech śledzą wyświetlenia i kliknięcia oraz korzystają z pixeli (np. tagów konwersji), aby mierzyć i raportować skuteczność kampanii reklamowych.
Poniżej pokazujemy jak działają pomiary w aukcjach RTB.
Privacy Sandbox
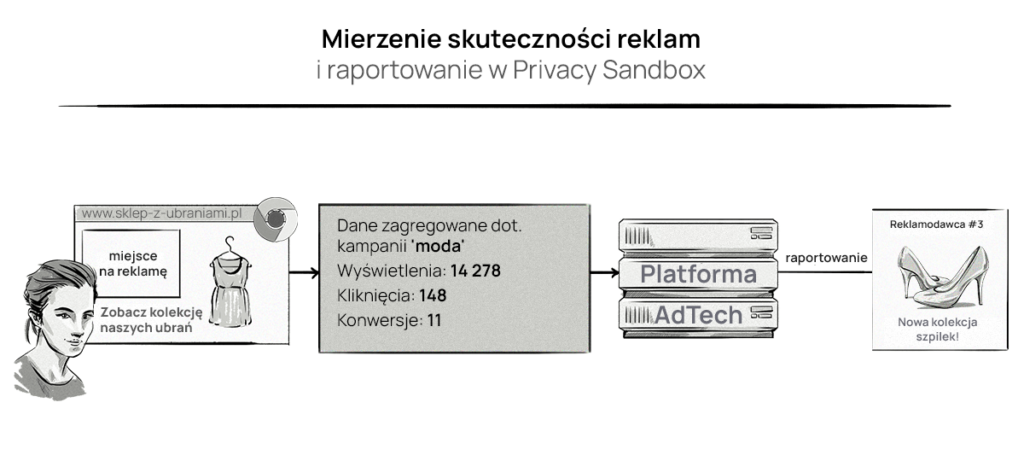
Privacy Sandbox proponuje API do mierzenia i raportowania kampanii reklamowych, zaprojektowane tak, aby unikać śledzenia między witrynami i dzięki temu chronić prywatność użytkowników sieci.
Aby firmy AdTechowe nie mogły skorelować kliknięcia lub konwersji z konkretnym użytkownikiem, raporty będą przesyłane w zagregowanej formie z modułu odpowiedzialnego za agregację, tworzonego na serwerze.
Poniżej pokazujemy, jak to może działać.
Możliwe rozwiązania
Od ogłoszenia przez Google decyzji o zrezygnacji z ciasteczek stron trzecich, firmy AdTech pokazały kilka możliwych rozwiązań do targetowania reklam i mierzenia skuteczności kampani reklamowych. Większość pomysłów opiera się na wykorzystaniu danych własnych (first-party data), zbieranych przez wydawców.
1. Wykorzystanie e-mail ID
Wydawca prosi użytkowników o utworzenie konta lub podanie adresu e-mail, aby mogli oni uzyskać dostęp do treści (np. artykułów).

Uzyskany adres e-mail wydawca zaszyfruje, a następnie używa jako identyfikatora (ID). Takie ID byłoby wykorzystywane do identyfikacji powracających użytkowników i kierowania do nich reklam.
E-mail ID mogą być łączone. Reklamodawcy korzystający z rozwiązań na bazie ID (np. od Trade Desk, LiveRamp, Tapad czy Neustar) mogą bowiem mieć własną bazę zaszyfrowanych identyfikatorów i łączyć je z ID otrzymanymi od wydawców.
Główną wadą tego rozwiązania jest skala i zasięg – nie każda strona internetowa wymaga podawania e-maila. Szacuje się, że zalogowane osoby będą stanowić około 20% procent internautów, co oznacza, że do pozostałych 80% nie będzie można wyświetlać reklam.
Przypomnijmy także, że celem Chrome jest unimożliwienie identyfikacji osób. Dlatego w przyszłości możnaby było spodziewać się ograniczenia skuteczności tej metody.
2. Wykorzystanie local storage
Pliki cookie nie są jedynym sposobem, w jaki przeglądarki internetowe mogą przechowywać dane. Na popularności zyskuje metoda pamięci lokalnej (local storage). Local storage może przechowywać identyfikatory użytkowników podobnie jak robią to ciasteczka.
Opcja ogranicza się do domeny wydawcy, co oznacza, że firmy AdTech nie mogłyby identyfikować użytkowników pomiędzy różnymi witrynami.
3. Nowa subdomena dla firm AdTechowych
Tworzenie nowej subdomeny tylko po to, aby trzymać na niej oprogramowanie nie jest niczym nowym, zwłaszcza dla platform MarTechowych.
Wydawcy mogą utworzyć subdomenę dla swoich partnerów (np. ssp.stronawydawcy.pl), dzięki czemu będą mogli tworzyć i zapisywać ciasteczka stron pierwszych (first-party cookies). Takie ciasteczka mogą być wykorzystane do identyfikacji użytkowników.
Główny problem tych rozwiązań
W pewnym sensie powyższe rozwiązania są realnymi zamiennikami ciasteczek stron trzecich, ale raczej na krótki okres. Większość z nich nie jest nakierowana na ochronę prywatności użytkownika.
Nawet, gdyby zbierać odpowiednie zgody od użytkowników i umożliwiać im łątwe wycofywanie tych zgód, to i tak każde rozwiązanie opiera się na identyfikacji poszczególnych użytkowników. Jak wspomnieliśmy wcześniej, nie idzie to w parze z polityką ochrony prywatności w Chrome i innych przeglądarkach, zwłaszcza Firefoxa i Safari.
Co zatem powinny teraz zrobić firmy AdTech?
Planowanie przyszłości, udział w dyskusjach o Privacy Sandbox i zmiany w technologiach to najlepsze, co firmy AdTechowe mogą dla siebie zrobić.
Biorąc pod uwagę ostatnie 5 lat w reklamie internetowej (RODO, ITP itp.), jasne jest, że przyszłość branży będą wyznaczać technologie i procesy skupione na ochronie prywatności internautów.
Dopóki Chrome nie wyłączy ciasteczek stron trzecich, firmy AdTechowe zachowają status quo. Ale dla własnego dobra powinny obserwować, co dzieje się na rynku.




